Big Developments In Big Data: 15 Must-See Products

Big Data In The Big Apple
The latest in big data technology was on display in New York last week at the Strata + Hadoop World big data conference and exposition. Some of the more than 160 exhibiting vendors unveiled new products or significant new releases of their software, including Altiscale, Clearstory, Cloudera and PepperData.
Many of the big data announcements at the Strata + Hadoop conference revolved around Hadoop, Apache Spark, data lakes, NoSQL databases and Microsoft Azure HDInsight. Here's a few that caught our attention.

Altiscale Data Cloud 4.0
Altiscale offers the Hadoop-based Big Data-as-a-Service that provides a way for businesses to use Hadoop without the complexity and expense of running the big data platform on site.
The 4.0 release supports all major versions of the Apache Spark processing engine and features major upgrades to core Hadoop components including YARN and the Hadoop distributed file system (HDFS) for increased performance, scalability and stability.
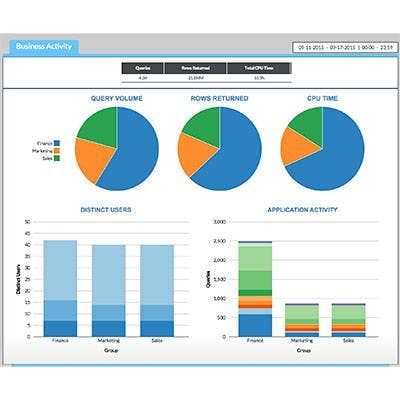
Attunity Visibility 7.0
Attunity unveiled this latest edition of its enterprise data usage analytics and monitoring software, which provides insight about business activity, data usage and workloads across Hadoop and enterprise data warehouses through a single console (pictured). Such visibility helps organizations scale Hadoop deployments and better adapt them to their business needs.
The company also showed off Attunity Replicate Express for Hadoop, a free edition of the company's data replication and loading software that automates the process of moving data into Hadoop and data lakes, supporting both batch and incremental data loading.
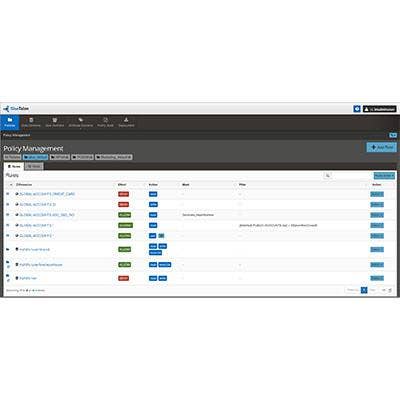
BlueTalon Policy Engine
BlueTalon develops data-centric security technology for Hadoop, SQL and other big data environments. At Strata + Hadoop the company unveiled new fine-grained data access control capabilities for the BlueTalon Policy Engine the company said provides filtering and dynamic masking capabilities directly on the Hadoop Distributed File System (HDFS).
The vendor said the new features offer a "catch-all security blanket" for Hadoop that blocks users from bypassing security controls to directly access HDFS data, but also eliminates the risks created by siloed security policies in specific applications.
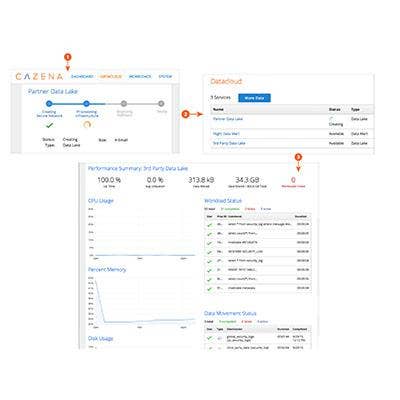
Cazena Big Data-as-a-Service
Cazena debuted its Data Lake-as-a-Service and Data Mart-as-a-Service solutions that the company said simplifies cloud-based big data processing.
The data mart service is designed for such workloads as analytics, ad hoc business intelligence and other SQL processing tasks. The data lake service is for staging, processing or archiving large volumes of data. Cazena said raw data could be staged and processed in the data lake service, and subsets of the data extracted and loaded into the data mart service for specific users and departments.
The service's capabilities include workload intelligence to maintain service level agreements, automation to move data in the cloud with connectors for data sources and business analytics tools, and security and privacy capabilities including data encryption.
ClearStory Data Intelligent Data Harmonization
ClearStory Data significantly enhanced its Apache Spark-native Intelligent Data Harmonization software that the company said helps everyday business people access and combine disparate data for analysis and data discovery applications -- what the company calls "data harmonization."
ClearStory has enhanced the software's data blending capabilities including smart data matching, a visual guided interface that simplifies the data integration process. Also new is the Data Lineage Visualizer that insures the integrity of data and analytical insights.
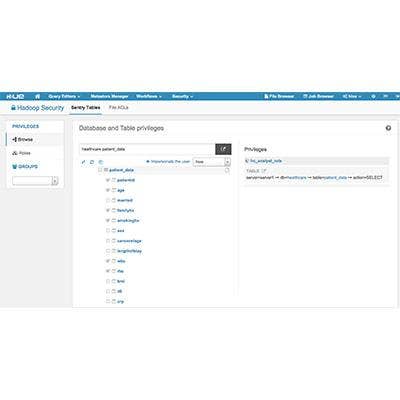
Cloudera RecordService and Kudu
Hadoop software developer Cloudera introduced RecordService (pictured), a unified role-based security policy enforcement system for the Apache Hadoop ecosystem. Available as a public beta, RecordService is a high-performance security layer for Hadoop software that provides complete row- and column-based security and dynamic data masking.
Cloudera also launched a public beta of Kudu, a new columnar data store system for Hadoop that enables fast analysis in real-time use cases. Complementing existing Hadoop storage options HDFS and Apache HBase, the new software is a Hadoop-native storage engine that supports both low-latency random data access and high-throughput analytics.
Dataguise Integration With Microsoft Azure HDInsight
Dataguise, which provides data discovery and data protection software for Hadoop and other big data environments, announced that its DgSecure software is now integrated with Microsoft's Azure HDInsight -- Microsoft's distribution of Hadoop on its Azure cloud platform.
The integration allows Dataguise to provide improved security and compliance on Azure-based Hadoop deployments. The software can detect, audit, protect and monitor sensitive data assets in such deployments in real time.
Dataiku DSS Spark Integration
Dataiku announced that its Data Science Studio is now integrated with the Spark data processing engine, improving DSS' processing speeds by 10 to 100 times faster. That means data analysts can process much larger data sets, up into the terabytes, and process it much more quickly.
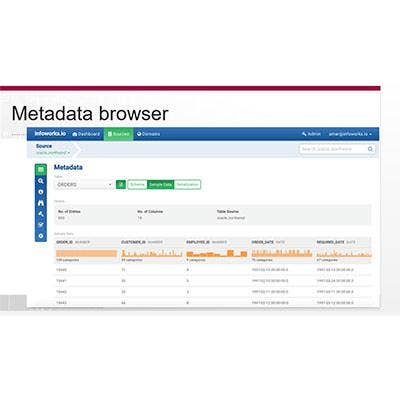
Infoworks Dynamic Data Warehousing
Startup Infoworks, exiting from stealth mode, debuted its Infoworks Dynamic Data Warehousing platform, a system that allows businesses to support all types of business analytics on a single Hadoop cluster.
Infoworks DDW crawls enterprise databases, collecting data, and ingests it into Hadoop. It also organizes the data into data warehouses, cubes and other models for a wide range of analytical applications. The system continuously synchronizes the stored data with data sources and supports a wide range of interfaces, including ODBC and SQL, to provide access to the data (pictured).
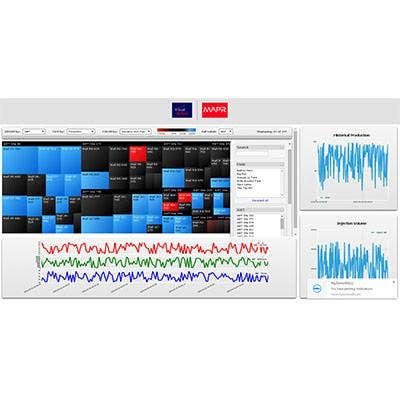
MapR Technologies' JSON Support For Document Database
Hadoop software developer MapR Technologies introduced native JSON support for its MapR-DB NoSQL database. The in-Hadoop document database will help developers build scalable JSON-based applications that leverage continuous analytics on real-time data.
JSON (JavaScipt Object Notation) is a lightweight data-interchange format. MapR's JSON support helps developers benefit from the advantages of a document database combined with Hadoop and Spark.
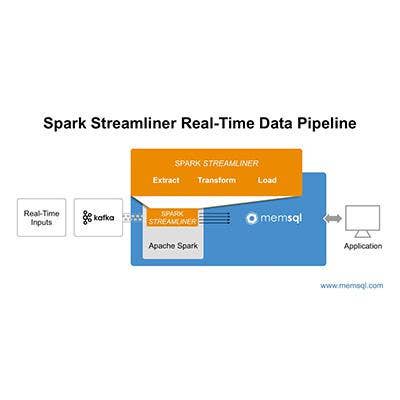
MemSQL's Spark Streamliner For Real-Time Analytics
In-memory database software vendor MemSQL introduced Spark Streamliner, an integrated Spark system that provides real-time analytics capabilities. MemSQL said businesses can leverage its database and Spark to deploy real-time data pipelines from multiple sources (such as Apache Kafka, as illustrated) for speeding up transactions and data analysis.
MemSQL said Spark Streamliner offers one-click deployment of Apache Spark, making the processing engine available for a broader range of use cases.
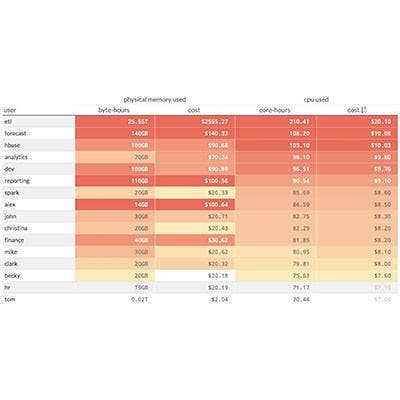
Pepperdata's Chargeback Reporting Tools For Hadoop Systems
Pepperdata, which develops software for real-time Hadoop cluster optimization, has added charge-back functionality to its software that makes it easier to measure and allocate costs associated with workloads across distributed systems. That, according to the company, should accelerate widespread adoption of Hadoop for general business processes.
The new functionality more effectively measures the amount of processing capacity-specific users or workloads require, making it easier to allocate costs back to departments that share a centralized, multitenant Hadoop deployment, the company said.

SnapLogic Elastic Integration Platform
SnapLogic showed off the fall release of its Elastic Integration Platform, the vendor's integration Platform-as-a-Service offering for big data applications.
SnapLogic's software has more than 300 pre-built connectors called "Snaps." The new release includes Snaps for the Spark data processing engine and the Cassandra NoSQL database. Also new is the Sparkplex technology, which gives organizations the option of running their data pipelines on Spark, especially for real-time processing tasks such as recommendation engines on retail websites.
Talend 6
Talend introduced a major new release of its data integration platform, recently renamed "Talend Data Fabric," with native support for Apache Spark and Spark Streaming. The support, built into the new Talend Big Data and Talend Real-Time Big Data components of the platform, provides 5x performance improvement for jobs converted from MapReduce jobs to Spark, according to the company.
The new release also offers enhancements for on-premise and cloud data integration, as well as for data quality and master data management.
Trifacta v3
Trifacta demonstrated version 3 of its software for "data wrangling," the process of transforming raw, complex data into clean, structured formats for analysis. The new release offers a range of improvements in security, including supporting Hadoop security standards such as Kerberos; metadata and lineage, including support for Cloudera Navigator and the Hive metastore; and support for operational applications such as Chronos and Tidal.
The new release also has a number of user-interface enhancements, including Transformation Suggestion Cards that provide visual representations of suggested data transformations (pictured). There are also expanded connectivity options to data sources such as Amazon Web Services, Amazon S3, Hive and XLS files.