The 10 Coolest Big Data Products Of 2017

Big Data: Hot Market, Cool Products
Worldwide spending for big data and business analytics hardware, software and services is projected to grow from $150.8 billion this year to $210 billion in 2020 – a compound annual growth rate of 11.9 percent, according to market researcher IDC.
While long-established business analytics and data management products account for most of that spending, every year there are a number of leading-edge products that move forward the capabilities of big data technology.
Here are 10 big data products that caught our attention in 2017.
Get more of CRN's 2017 tech year in review.
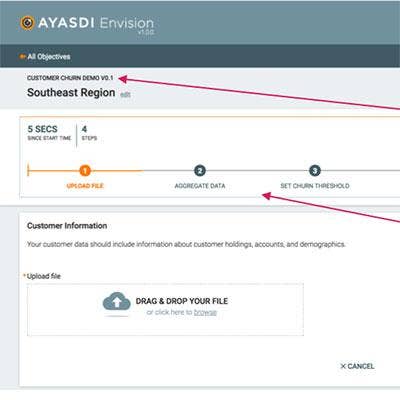
Ayasdi Envision
Ayasdi develops a machine intelligence platform that businesses and organizations use to run big data applications.
Ayasdi Envision, which debuted in June, is a framework for developing intelligent applications that run on the Ayasdi platform and take advantage of its artificial intelligence and machine learning capabilities.
Envision, according to the company, opens the whole process of developing and deploying intelligent applications to a wider audience of knowledge workers and improves the usability of analytical workflows for users.
At the same time of the Envision launch, the company also debuted the Ayasdi Model Accelerator, a new intelligent application for developing models specifically for the financial services industry.
Cloudera Altus
Businesses are increasingly turning to the cloud to run their data processing and analytics operations. In May big data platform developer Cloudera launched Cloudera Altus, a Platform-as-a-Service system for running large-scale data processing applications in a public cloud system.
The first available platform component was Cloudera Altus Data Engineering, a service that simplifies the development and deployment of elastic data pipelines used to provision data to Apache Spark, Apache Hive, Hive on Spark and MapReduce2 systems.
Data engineers can use the service, available on Amazon Web Services, to run direct reads from and writes to cloud object storage systems without the need for data replication, ETL tools or changes to file formats.
On Nov. 28 the company debuted Altus Analytic DB, a cloud-based data warehouse service that delivers self-service business intelligence and SQL analytics to everyday users. Altus Analytic DB uses the high-performance Apache Impala SQL query engine. A beta version of the product is expected to be available shortly.
Confluent KSQL
Confluent has garnered attention for the software it has developed around the Apache Kafka open-source stream-processing platform. In August Confluent debuted KSQL, an open-source streaming SQL engine that enables continuous, interactive queries on Kafka.
KSQL allows developers familiar with SQL to build applications that work with Kafka. Because so many programmers are schooled in SQL, KSQL will make Kafka's stream-processing capabilities available to a wider audience to address the challenge of developing interactive queries for streaming big data.

FlureeDB
Blockchain technology, originally developed for managing digital currencies like Bitcoin, is essentially a digital ledger that allows information to be distributed but not copied. It has been getting a lot of attention this year as businesses discover blockchain's potential use for a range of applications that require ensuring the integrity and security of transactional data.
FlureeDB, launched in November as a public beta, is a scalable blockchain cloud database that makes it easier for companies and developers who want to integrate blockchain technology into their existing IT infrastructure and business applications. It's seen as a key enabler as businesses increasingly run on decentralized applications.
Fluree PBC (public benefit corp.), the developer of FlureeDB, is the brainchild of Platinum Software founder CEO Flip Filipowski and SilkRoad Technology founder and CEO Brian Platz.

Hortonworks Dataflow 3.0
DataFlow is Hortonworks' "data-in-motion" platform that's used to collect, curate, analyze and act on data in real time across on-premise and cloud systems. The software is designed to help organizations tackle the growing volumes of streaming data from mobile devices, sensors and Internet of Things networks.
DataFlow 3.0, which debuted in June, provides capabilities designed to make it easier for solution provider partners, ISVs and customers to develop streaming analytical applications – an increasingly important requirement for real-time analysis and IoT applications.
HDF 3.0 introduced Streaming Analytics Manager, a toolset that allows application developers, business analysts and administrators to design, build, test and deploy streaming applications on HDF without coding. The new edition also included a new repository of shared schemas that interact with data streaming engines, including Apache Kafka, Apache Storm and Apache NiFi, providing improved data governance and operational efficiencies.
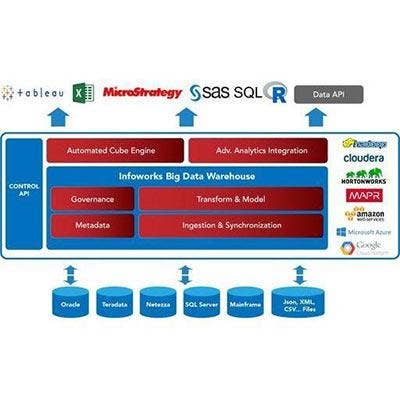
Infoworks Cloud Big Data Warehouse
In September Infoworks launched the Infoworks Cloud Big Data Warehouse, an end-to-end data warehouse platform in the cloud that businesses use to quickly build and deploy big data analytics systems.
Running on Amazon Web Services, Microsoft Azure and Google Cloud, Infoworks Cloud Big Data Warehouse automates such tasks as enterprise-to-cloud data ingestion and synchronization, data transformation, and building data models and cubes.
Infoworks, based in San Jose, said the level of automation provided by its system helps businesses rapidly design and deploy big data analytics applications without coding. The system is designed for such use cases as enterprise data warehouse augmentation, advanced analytics, self-service business intelligence, and ETL (data extract, transform and load) offload.

Kyvos 4.0
Kyvos Insights develops a cloud-based big data analytics platform that provides OLAP (online analytical processing) for huge volumes of data stored in Hadoop-based data lake systems.
In August Kyvos launched the Kyvos 4.0 edition of its platform offering a "quantum" jump in the software's scalability in both the amount of data it can process and the number of concurrent users it can support—the latter through a new active-active load balancing architecture that can scale to thousands of users.
The 4.0 release also provided access to more data through a wider range of business intelligence tools, and new security capabilities for protecting data sources. It also supported more elastic deployments through the ability to re-size query servers based on usage needs, handling increased workloads or decreased demand during off-peak hours.

Podium Data Conductor
Businesses have been assembling data lakes, huge stores of generally raw, unorganized data – often built on Hadoop. The challenge is finding a way to tap into all that data's potential value. Podium develops the Podium Data Marketplace platform for building centralized repositories of clean, well-documented data that's accessible to a broad range of users.
In September Podium launched Data Conductor, a toolset that helps data managers, compliance professionals and business users manage, discover and access all data on any platform within an enterprise. Data Conductor, an integral part of the Podium platform, works with data within on-premise databases and operational systems, or third-party public cloud sources.
In October Podium also added "Intelligent Data Identification" to its platform, a tool that combines a smart data catalog with a pattern recognition engine to identify duplicate data, improve data governance and reveal potential data corruption problems.

Snowflake Computing Data Sharing And Snowpipe
Snowflake Computing, a leading San Mateo, Calif.-based provider of cloud data warehouse services, debuted two products that caught people's attention in 2017: Snowflake Data Sharing and Snowflake Snowpipe.
Snowpipe addresses the fact that more businesses are storing huge volumes of data in AWS Simple Storage Service (S3) – an accelerating trend given the rapidly falling cost of cloud data storage – and are looking for ways to tap into that data to support decision-making tasks.
Snowpipe detects and collects data streaming into S3 and moves it to the Snowflake Computing data warehouse for near-real-time analysis and customer-facing applications.
Snowflake Data Sharing is an extension of the company's data warehouse service that allows subscribers to securely share live data among themselves, establishing one-to-one, one-to-many and many-to-many data sharing relationships.
With the data sharing service a company can link data silos across multiple business units to get a comprehensive view of a company's operations or share data with its customers, partners and suppliers to reduce costs and improve efficiencies.
StreamSets Data Collector Edge
More data being generated today is coming from the edge of IT networks, including Internet of Things devices, IoT sensors in industrial equipment, and the endpoint systems used in cybersecurity applications. The challenge is efficiently collecting all that data.
StreamSets develops a data operations platform for managing the life-cycle of "data in motion." In November the San Francisco-based company debuted StreamSets Data Collector Edge, open-source data ingestion software for resource- and connectivity-constrained systems at the edge of IT networks.
The software is a slimmed-down version of the StreamSets Data Collector product that takes up only 5MB, making it ideal for IoT and cybersecurity edge devices. Today data ingestion logic for such applications is often custom-coded for specific devices.
Based on the Go programming language, SDC Edge supports a range of operating systems including Linux and Android. It performs computations such as data normalization, redaction and aggregation, and is architected to support full-featured edge analytics including machine and deep-learning models.