The 10 Coolest Big Data Tools Of 2021
Working with ever-growing volumes of data continues to be a challenge for business and organizations. Here are 10 cool big data tools that caught our attention in 2021.

Big Data, Bigger Challenges
See the latest entry: The 10 Hottest Big Data Tools of 2022
The global COVID-19 pandemic hasn’t slowed the exponential growth of data: IDC recently calculated that 64.2 zettabytes of data was created, consumed and stored globally in 2020. And the market researcher forecasts that global data creation and replication will experience a 23 percent CAGR between 2020 and 2025.
The good news is that innovative IT vendors, both established companies and startups, continue to develop next-generation tools for a range of big data management tasks including data observability, data governance, metadata management and data quality management. And there are tools for connecting data sources scattered across hybrid and multi-cloud IT systems—critical for managing distributed analytical and operational big data workloads.
Here’s a look at some cool big data tools that caught our attention in 2021.
For more of the biggest startups, products and news stories of 2021, clickhere.

Alation Cloud Service
Alation has been expanding its original data catalog software into a broad platform for a range of enterprise data intelligence tasks including data search and discovery, data governance, data stewardship, analytics and digital transformation.
In April the Redwood City, Calif.-based company extended those capabilities to the cloud with its new Alation Cloud Service, a comprehensive cloud-based data intelligence platform that can connect to any data source—in the cloud or on-premises—through cloud-native connectors.
The new cloud offering, with its continuous integration and deployment options, provides a simple way to drive data intelligence across an organization’s hybrid architecture with lower maintenance and administrative overhead and faster time-to-value.
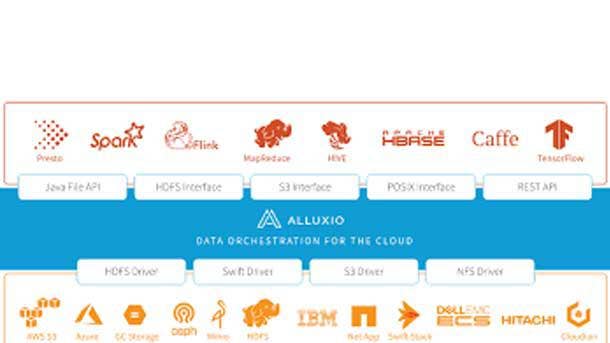
Alluxio Data Orchestration Platform
In November Alluxio launched version 2.7 of the Alluxio Data Orchestration Platform, the San Mateo, Calif.-based company’s software for managing large-scale distributed data workloads and connecting data sources scattered across hybrid and multi-cloud IT systems.
Alluxio’s software is a virtual distributed file system that separates compute from storage and makes all data appear local no matter where it’s stored. That unifies access to distributed data, providing a way to link business analytics and data-driven applications to distributed data sources and making management of distributed data more efficient.
The new 2.7 release provides a five-fold improvement in I/O performance efficiency for machine learning training by parallelizing data loading, data pre-processing and training pipelines. The new edition also offers enhanced performance insight and support for open table formats like Apache Hudi and Iceberg, allowing the system to scale up access to data lakes for faster Presto- and Spark-based analytics.
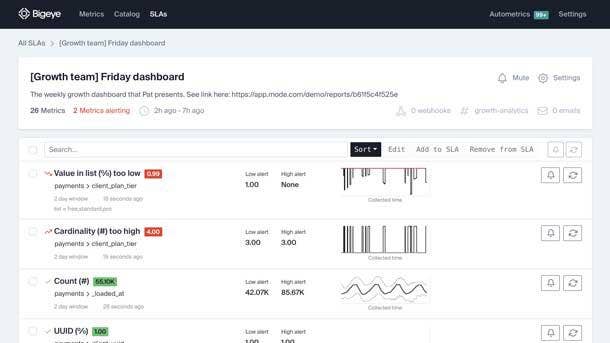
BigEye
Delayed, missing, duplicated and damaged data can hinder big data initiatives. But detecting problems using manual data engineering approaches is no longer feasible given the increasing volumes of data businesses are generating today.
BigEye is a San Francisco-based startup in the data observability space that develops software tools for measuring, improving and communicating the quality of data used for self-service business analytics, machine learning models and other data-intensive tasks.
BigEye’s data observability platform, including its Autometrics, Autothresholds and Integrations products, monitors the quality of data as it flows between systems, helping data management teams identify and fix data quality problems and maintain data integrity.
The Bigeye system, offered as a fully managed SaaS service as well as for on-premises/private cloud use, instruments data sets and data pipelines, applying metrics to monitor and measure data quality, detects data anomalies, and alerts data managers when issues occur.

Cribl LogStream Cloud Enterprise Edition
Cribl, another startup in the data observability arena, in October debuted LogStream Cloud Enterprise Edition, a cloud service for securely managing globally distributed observability data pipelines.
San Francisco-based Cribl’s LogStream is used to build pipelines for routing high volumes of telemetry data—including machine log, instrumentation, application and metric data—between operational, storage, analytical and security IT systems.
The LogStream Cloud edition makes it possible for businesses and organizations to centrally configure, manage, monitor and orchestrate data observability pipeline infrastructure anywhere in the world.

Databricks Delta Sharing
Databricks launched the Delta Sharing initiative in June to create an open-source data sharing protocol for securely sharing data across organizations in real time, independent of the platform on which the data resides.
Delta Sharing, included within the open-source Delta Lake 1.0 project, establishes a common standard for sharing all data types—structured and unstructured—with an open protocol that can be used in SQL, visual analytics tools and programming languages such as Python and R. Large-scale datasets also can be shared in the Apache Parquet and Delta Lake formats in real time without copying.
Delta Sharing is the latest open-source initiative from Databricks, one of the most closely watched big data startups in recent years. Founded by the developers of the Apache Spark analytics engine, San Francisco-based Databricks markets the Databricks Lakehouse Platform, its flagship unified data analytics platform.
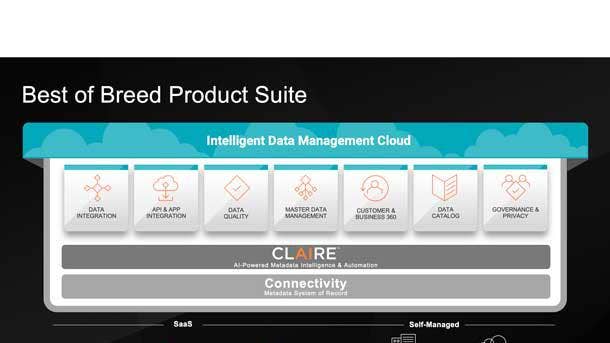
Informatica Intelligent Data Management Cloud
The Intelligent Data Management Cloud, unveiled in April, is New York-based Informatica’s flagship platform providing a number of data management capabilities that are key to digital transformation initiatives. The AI-powered system provides some 200 services covering data integration, application and API integration, data quality, master data management and customer data management.
In July Informatica expanded the platform’s capabilities with Unified Data Governance and Catalog, a cloud service that businesses and organizations use to modernize their data governance programs and improve the trustworthiness of the data they use for business intelligence and other data-driven tasks.
Informatica, which was once a public company before being acquired and taken private in 2015, became a public company again in October.

Molecula FeatureBase
Molecula FeatureBase is an enterprise feature store that the company said “simplifies, accelerates and controls” access to big data for real-time analytics and machine learning applications.
In October market researcher Gartner included Molecula in its “Cool Vendor” report on data management companies.
Founded in 2019 and based in Austin, Texas, Molecula raised $17.6 million in Series A financing in January, capital the startup applied to accelerating the launch of Molecula Cloud and to expanding sales and marketing efforts.

Monte Carlo
Monte Carlo’s data observability software is used to monitor data across IT systems, including in databases, data warehouses and data lakes, to gauge and maintain data quality, reliability and lineage—what the company calls “data health.”
The San Francisco-based startup’s platform evaluates data according to its freshness and how up to date it is, the volume or completeness of data tables, the data schema or organization of the data, data lineage including sources and usage, and the data’s distribution (whether the data’s values are within an accepted range).
Monte Carlo’s technology applies to data sources and pipelines similar practices used in DevOps including automated monitoring, alerting and triaging to evaluate data quality and identify problems.
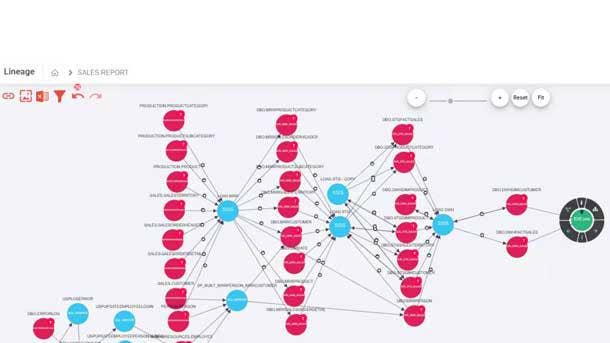
Octopai Data Lineage XD
Octopai develops software tools that automate metadata management and analysis, helping organizations locate and understand their data for improved operations, data quality and data governance.
Octopai’s Data Lineage XD, which debuted earlier this year, is an advanced, multi-dimensional data lineage platform that the Rosh Haayin, Israel-based company said takes data lineage to the next level.
Data Lineage XD uses visual representations to display data flow from its source to its destination, providing users with a more complete understanding of data origin, what happened to it and where it is distributed within a data landscape. Such capabilities are used to track data errors, implement process changes, manage system migrations and improve business analytics efficiency.

YugabyteDB And Yugabyte Cloud
Yugabyte is one of a new generation of database developers offering technology designed to outperform and outscale legacy database systems. YugabyteDB is a high-performance, distributed SQL database for building global, internet-scale applications.
In September Sunnyvale, Calif.-based Yugabyte launched Yugabyte Cloud, a fully managed Database as a Service based on YugabyteDB for building cloud-based applications and moving legacy applications to the cloud.
One month earlier Yugabyte released YugabyteDB 2.9 with a smart JDBC client driver with an understanding of the distributed architecture of a YugabyteDB cluster. The new release also offers distributed transactional backups, fine-grained point-in-time recovery, transaction savepoints and the use of RPC compression to reduce network bandwidth usage.