The 10 Biggest Cloud Outages Of 2014 (So Far)

No Cloud Is Perfect
Computers, like people, are never perfect. But the expectation with clouds is that the servers businesses and consumers rely on are up and smoothly running 99.999 percent of the time. That's just 5.26 minutes of downtime per year.
But outages happen. Here are some of the most notable so far this year, in chronological order.

Dropbox, Jan. 10
The cloud storage company underwent a global outage beginning at about 8:30 pm EST.
In a postmortem, Dropbox said it was upgrading the OS on some of its machines that store databases used for features like photo album sharing and camera uploads, but not its core business of file storage. A subtle bug in the upgrade script tried to reinstall an OS on an active machine, and the system went haywire.
The Dropbox website returned server error messages and desktops and mobiles wouldn't file sync.
Most of the service was recovered from backups within three hours, but full core service was not fully restored for two days.

Samsung , April 21
A fire erupted Easter morning at a datacenter in Gwacheon, South Korea, and Samsung smartphones and tablets around the world were painfully separated from their data for the next several hours.
The fourth floor inferno also caused problems with credit card services, Samsung's Smart TV and other devices that use Samsung servers.
Experts wondered why so many servers were centralized in one location and why no redundancy with other sites was built into the system.

Adobe Creative Cloud, May 14
The online versions of Adobe's most popular applications were unavailable for more than 24 hours, beginning in the early evening of May 14 when subscribers on the East Coast reported having trouble signing into the service.
Adobe blamed the outage on a system maintenance problem, and all was well the following afternoon.
Adobe's Creative Cloud totals 16 applications, including Photoshop, Acrobat, InDesign and Premiere Pro.

Internap, May 16
An uninterruptable power supply system failed at Internap's New York City datacenter after a utility power outage blacked out the region. The cloud service provider went down at 3 a.m., impacting customers using colocation and IP connectivity services.
Internap remained down for seven hours.
The outage took out streaming video platform Livestream and the StackExchange network of sites popular among developers.

Joyent, May 27
Cloud service provider Joyent saw its East Coast datacenter go down because of an error a system administrator initiated during a remote capacity upgrade.
According to Joyent's postmortem, the operator was performing routine upgrades when he inadvertently caused all East Coast API systems and customer instances to be rebooted simultaneously that afternoon.
Minimum downtime was 20 minutes and most customers were up and running within half an hour, but a small number waited more than two hours to get back into the system because of a bug in a network card driver running on some of the legacy hardware platforms.
Microsoft Lync, June 23
The instant messaging and VoIP service, part of the Office 365 suite of cloud-based business products, went down on June 23 in much of North America before noon EST.
For some users, the outage, which Microsoft said was caused by "external network failures," lasted up to eight hours.
Microsoft said connectivity was restored in minutes, but an ensuing traffic spike overloaded their network and extended the outage. Customers complained Microsoft was not keeping them apprised of what was happening.
Microsoft Exchange, June 24
With the Lync outage fresh in the minds of Microsoft users, Microsoft's hosted email service, Exchange Online, suffered a similar fate the next day. Microsoft said the back-to-back Office 365 failures were unrelated.
The Exchange outage, which kept some customers out of their email for up to nine hours that Tuesday, was caused by an "intermittent failure in a directory role that caused a directory partition to stop responding to authentication requests," according to Microsoft.
The Lync and Exchange outages were aggravated by comments Microsoft tweeted the very next day -- and later conceded were ill-timed -- in which the company boasted about its speedy customer support.

Verizon Wireless, June 27
Verizon Wireless suffered a widespread outage that brought down parts of its billing system, preventing customers from being able to access their online accounts, pay bills or, in some cases, upgrade their phones.
The system-wide outage lasted about a day, not only impacting customers who use the My Verizon online portal, but also Verizon's own retail stores.
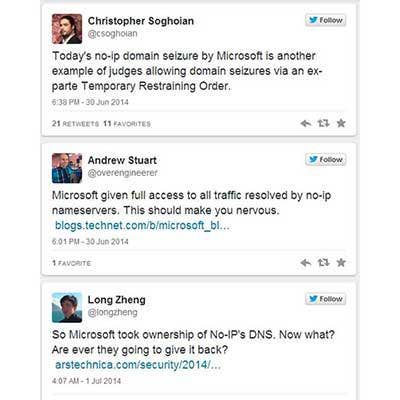
No-IP.com Seizure Outages, June 30
While probably not as significant an outage when measured on a scale of economic productivity, this one was more infuriating because it was caused by an intentional act.
Microsoft, citing cybercrime perpetrated against its users, seized 23 domains from No-IP.com, a Reno, Nev.-based provider of free dynamic DNS services. In doing so, the software giant also took out service for 1.8 million legitimate No-IP.com customers for more than two days.
Among them was SonicWall, a network security vendor acquired by Dell in 2012, which said hundreds of its customers, including buildings that run security surveillance cameras using No-IP.com's dynamic DNS service to relay video feeds, were offline.
A federal court transferred DNS authority over the domains to Microsoft, which argued they were launching pads for malware attacks.

Autotask, July 1-2
Capacity spikes caused two separate failures at data centers powering CRM and business IT provider Autotask.
The system went down the evening of July 1, at which point engineers added more virtual cores to the web tier. But the CPU problems continued, and the system failed again the next day.