Data Quality Tech Startup Bigeye Raises $17M In Series A Funding
With its data quality engineering platform the company aims to bring to data operations the kind of practices found in DevOps and IT management.
Big data startup Bigeye has raised $17 million in Series A funding, the company said Thursday, providing resources the company will devote to accelerating development of its data quality engineering platform and expanding its go-to-market efforts.
The funding round was led by Sequoia Capital with participation from existing investor Costanoa Ventures. The round brings the San Francisco-based company’s total financing to $21 million, including $4 million in seed funding the company raised last year.
“We’ve spent a lot of time, relatively, heads down developing product for the last year,” said co-founder and CEO Kyle Kirwan, in an interview with CRN. While the development work will continue, the company also will devote resources to extending the startup’s market reach with more sales and marketing people and initiatives.
[Related: 10 Cool Tech Companies That Raised Funding In March 2021]
That includes working with channel partners such as data engineering and consulting firms Method360 and Raybeam, Kirwan said.
As businesses and organizations wrestle with rapidly increasing volumes of data for operational and business analytics tasks, maintaining the integrity of data operations becomes a major challenge. Delayed, missing, duplicated and damaged data can hinder big data initiatives, but detecting those problems using manual data engineering approaches is no longer feasible.
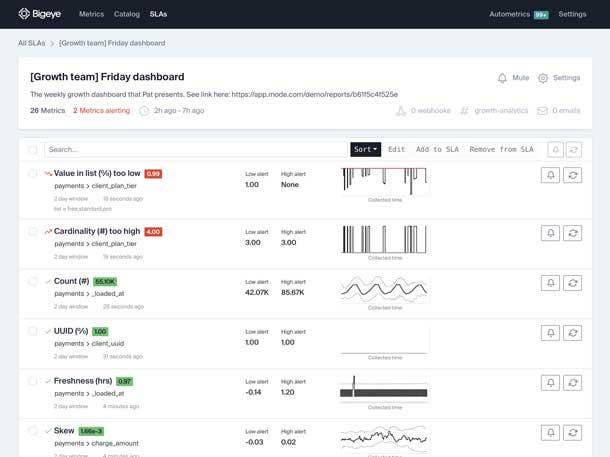
Bigeye’s data quality engineering platform helps data management teams identify and fix data quality problems. The system instruments data sets and data pipelines, applying metrics to monitor and measure data quality, detects data anomalies, and alerts data managers when issues occur.
The Bigeye system, which is available for on-premises/private cloud use and as a fully managed SaaS service, uses JDBC connectors and a read-only account to connect to data sources and collect health metrics. The system provides a dashboard (see above) with operational data metrics, SLAs and alerts.
The software works with a number of big data systems such as Snowflake, Google BigQuery and Amazon Redshift.
Kirwan and CTO Egor Gryaznov co-founded Bigeye – originally called “Toro” – in 2019 after working on the data management team at Uber. They recognized that operational data management processes lacked the kind of practices and tools found in software DevOps and IT infrastructure management, including anomaly detection, incident management and service level agreements.
“Everybody has had a data quality problem at some point,” Kirwan said. “Coming from Uber, we learned that you can’t solve these problems manually all the time as the data gets beyond a certain size. And I think, increasingly, businesses are reaching that size – faster and faster. So that means the products they use to manage their data also have to be intelligent.”
“The approach that we take is very similar to the monitoring systems you would see for [IT] infrastructure,” Kirwan said. Where IT monitoring systems might follow metrics such as CPU utilization or disk space capacity, for example, Bigeye’s system looks inside an organization’s data pipeline and examines such metrics as data flows and data refresh rates, he said.
Kirwan is careful to distinguish Bigeye’s data operations software from data cleansing and related tools marketed by vendors of data ETL (extract, transform and load) software.
Going forward, Kirwan said Bigeye will extend the capabilities of its platform beyond automated data anomaly detection to encompass the entire data quality engineering workflow. That includes adding tools and SLAs for tracking data management incidents, quantifying how often operational data problems occur, identifying their root cause, facilitating problem resolution and communicating data process changes and improvements to an organization’s managers and users.