Nvidia Shows Arm CPUs Run ‘Neck And Neck’ With x86 For AI
‘First of all, it shows that Arm as an acceleration platform can deliver performance that is just about on par with similarly configured x86 server,’ an Nvidia representative says about new AI performance comparisons that were made based on peer-reviewed data. However, one partner says it will take a major performance advantage for his customers to switch from x86 to Arm: ‘Among our customers, there needs to be some large, clear selling point of why they need to change to a new architecture.’
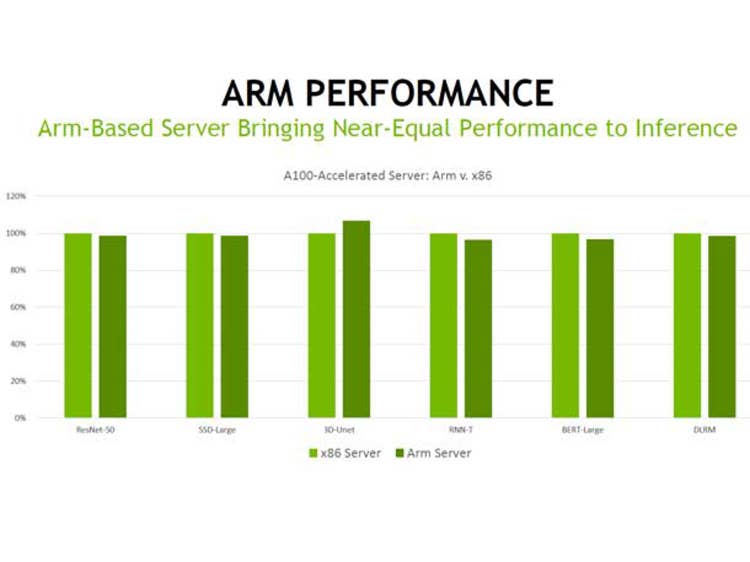
Nvidia said it has proven that Arm-based CPUs can provide nearly the same level of performance as x86-based CPUs when paired with GPUs for AI applications, specifically machine learning inference.
The Santa Clara, Calif.-based made the assertion this week and backed it up using peer-reviewed performance data that was released Wednesday as part of test results from several OEMs and chipmakers for the new MLPerf Inference v1.1 machine learning inference benchmark suite.
[Related: Arm Says New Neoverse V1, N2 Server CPUs Faster Than Intel, AMD]
In a briefing with journalists and analysts, Dave Salvator, senior product manager for AI inference and cloud at Nvidia, said the company determined the comparable inference performance between Arm-based CPUs and x86-based CPUs by taking the MLPerf results of an Arm-based GPU system and an x86-based GPU system and comparing them on a per-accelerator basis.
“We’re able to deliver results that you see here are running pretty much neck and neck with a very similarly configured x86 server,” he said.
When looking at the performance provided by one accelerator, Nvidia found that the test results between the Arm-based system and the x86-based system were similar, with the x86-based system only showing a minor advantage for five of the six machine learning models tested in offline settings, which included BERT-Large for natural language processing and RRN-T for speech recognition. For the 3D U-Net medical imaging model, the Arm-based system had a clearer advantage.
When it came to tests that required an online connection, the Arm-based system had a slight performance advantage for the ResNet-50 image classification model while the X86-based system had similar advantages for the SSD-Large object detection and DLRM recommendation models. However, with the RNN-T and BERT-Large models, the x86-based system had a much greater advantage.
The mostly similar performance results between an Arm-based system and an x86-based system represent “an important milestone,” according to Salvator.
“First of all, it shows that Arm as an acceleration platform can deliver performance that is just about on par with a similarly configured x86 server,” he said. “It’s also a statement about the readiness of our software stack to be able to run the Arm architecture in a data center environment.”
The Arm-based system, in this case, was a Gigabyte server running an Altra CPU from the semiconductor startup Ampere Computing and four Nvidia A100 GPUs connected via PCIe. The x86-based system was Nvidia’s DGX A100, which comes with two AMD EPYC 7742 CPUs and eight Nvidia A100 GPUs connected via SXM connectivity. Nvidia also showed similar performance comparisons between the same Arm-based system and a different x86-based system using the same CPUs and GPUs but with PCIe.
In a statement to CRN, Salvator said comparing the systems on a per-accelerator basis was the best way to make the data directly comparable since the Arm-based system and x86-based systems have a different number of CPUs and GPUs. He added that it’s a fair way to make a comparison, given that “inference performance scales linearly with the number of GPUs.”
“By going to a per-accelerator or per-processor comparison, we‘re able to directly compare one against the other and really get a sense of the relative performance,” he said.
David Kanter, executive director of MLCommons, the consortium that reviews and releases the MLPerf test results, told CRN that measuring performance per processor in the case of CPU-based systems or per accelerator in the case of GPU-based systems is a “fairly commonly used” metric.
“Per-processor performance numbers make sense because inference is generally an explicitly parallel workload,” he said in an email. “Each inference is independent, so [it] could in theory go to a separate processor and thus normalizing is reasonable.”
However, he noted, MLCommons “only officially endorses the measured MLPerf score,” which is based on the performance of the total system, not a single accelerator or processor.
Nvidia made its new argument about Arm in the data center as it hopes to make the alternative chip architecture a big part of its future. The chipmaker is trying to acquire Arm for $40 billion, even as it faces heavy scrutiny from regulators and opposition from some competitors and ecosystem players. The company also plans to make its own Arm-based data center CPUs.
Eliot Eshelman, vice president of strategic accounts and high-performance computing initiatives at Microway, a Plymouth, Mass.-based Nvidia partner, told CRN that his HPC customers would need to see a major performance advantage to make the jump from x86 to Arm, which hasn’t happened yet. Showing that the two chip architectures are merely comparable is not enough for them.
“Among our customers, there needs to be some large, clear selling point of why they need to change to a new architecture,” he said.
Eshelmen said Arm could eventually come out with architectural improvements that would give it a major advantage over Intel and AMD for AI, but he thinks it’s more likely that performance advancements will come from the interconnect work Nvidia plans to do between the CPU and the GPU for the chipmaker’s upcoming Arm-based data center CPUs.
“I don’t know if it will be so much that Arm is carrying the day and offering this huge multiplier over x86, or it’s just the path that Nvidia takes to get their end going,” he said.