The 10 Coolest Big Data Products Of 2014

The Big Market For Big Data Technology
Sales of big data hardware, software and services are expected to reach $28.5 billion this year and $50.1 billion in 2015, according to market research organization Wikibon. A.T. Kearney forecasts that global spending on big data technology will grow at a CAGR of 30 percent a year through 2018, reaching $114 billion.
There are a lot of cool big data products out there -- it seems like new products hit the market every day. Here's 10 that particularly caught our attention this year.
Be sure to check out the rest of CRN's 2014 product coverage.

Alpine Data Labs Chorus 5.0
Data analysis isn't an easy task for trained data scientists, let alone everyday business users. Alpine Data Labs touts its Chorus advanced predictive analytics software as sophisticated, and yet easy to use, thanks to the web-based software's "code-free" visualization capabilities and collaboration features. Chorus can work with data in Hadoop, as well as other data sources, such as the Oracle database and Microsoft's SQL Server.
Alpine Data Labs introduced the first Chorus release in February. Chorus 5.0 debuted in October with a new framework for integrating and managing R, Spark and other technologies. It also offered new tools that business executives use to oversee and manage their analytics ecosystems.
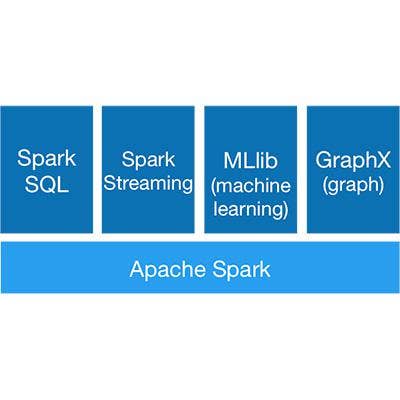
Apache Spark
Apache Spark is a powerful in-memory, data-processing engine that's getting a lot of attention in the big data arena.
The open-source Spark turbo-charges big data platforms like Hadoop or runs on a stand-alone basis. While Hadoop is a de facto standard for big data computing, it has its shortcomings, including its reliance on the MapReduce architecture that's more suitable for batch-processing rather than working with realtime, streaming data.
Developed by the Apache Software Foundation, Spark can run large-scale data-processing applications 100 times faster than Hadoop MapReduce. Spark 1.0 was released in May, and Spark 1.1.1 is the current release.
Cloudera Enterprise 5
Most of the leading Hadoop distribution vendors, including Hortonworks and MapR Technologies, launched product updates in 2014. But we're zeroing in on the April launch of Cloudera Enterprise 5, a major release of Cloudera's Hadoop-based platform, because of its significant advances in centrally managed security, tools for corporate governance and compliance, and comprehensive data management -- the latter thanks to the inclusion of Hadoop YARN resource management technology.
Cloudera also scores points for its Cloudera Connect partner program: When Cloudera Enterprise 5 debuted, the vendor announced that 96 partner products were integrated with the software. And if that weren't enough, Cloudera gained lots of attention by scoring a whopping $900 million in venture funding around the same time.

DataGravity Discovery Series
After a long gestation period, Nashua, N.H.-based DataGravity exited stealth mode in August and unveiled its data-aware DataGravity Discovery Series storage and analysis appliance. While the product has been on the market only for a couple of months, channel partners and customers have been giving the technology rave reviews.
DataGravity modestly says it is "revolutionizing storage and data management." It certainly provides an alternative to "dumb" storage-area networks. The DataGravity system marries flash storage with data search and governance tools, and data visualization capabilities, providing businesses with a way to gain actionable insights from their data, streamline data management and reduce business risks.

Elasticsearch 1.0
Elasticsearch says it's on a mission to make massive amounts of data available to businesses. Toward that end, in February the company debuted release 1.0 of its Elasticsearch search and analytics software for working with big data. The software is part of the company's open-source ELK stack that includes Elasticsearch, Logstash (log management) and Kibana (log visualization) software.
Elasticsearch is competing with Solr, the open-source search technology from the Apache Software Foundation. Many reviewers, users and solution providers give both technologies high marks. So it will be interesting to see if both gain traction, or if one or the other wins out.

MemSQL v3
MemSQL is a distributed, in-memory database that's part of the new generation of database technologies emerging to handle the huge volumes of data being generated by today's IT systems. The company claims it's the fastest in the world. The product can perform realtime analysis of transactional data and makes realtime performance a reality on Hadoop.
The product debuted in June 2012, and in September the company launched MemSQL 3.0 with a flash-optimized columnar data store and automatic cross-data-center replication. People have taken notice: Also in September In-Q-Tel, the investment firm that works with the U.S. intelligence community, acquired a stake in MemSQL, with an undisclosed value.
Salesforce.com Wave
Salesforce launched Wave, its cloud analytics platform backed by a NoSQL database, at the company's Dreamforce conference in October. The software can analyze sales, marketing and service data from Salesforce apps and other sources. It also provides businesses with tools for building custom mobile analytical applications.
A data analysis product had been anticipated from Salesforce even before it acquired cloud analytics startup EdgeSpring in June 2013. Some analysts, observers and competitors have dismissed Wave as little more than relatively simple visualization tools. But that's missing the point. Rather than bleeding-edge technology, Salesforce Wave is a data analytics toolset with which everyday business users can work. When tied into Salesforce's cloud applications that are used by millions of people, Wave could be an industry game-changer.
SAS In-Memory Statistics For Hadoop
SAS, the largest company focused exclusively on business analytics and related technology, released its In-Memory Statistics for Hadoop software in March. Based on the same in-memory analytics technology that underlies the popular SAS Visual Analytics software, this new software offers the ability to manage, explore, score and analyze massive amounts of data in Hadoop.
The "cool factor" here is the software's performance and advanced analytical capabilities.
It offers an interactive programming environment for building and comparing analytical models, and supports a number of statistical and machine learning modeling techniques, including clustering, regression, analysis of variance, decision trees, random decision forests, text analytics, recommendation systems and more.

Splice Machine 1.0
Splice Machine's realtime relational database is designed to help businesses get around Hadoop's batch-analytics limitations by offering a full-featured, transactional SQL database on Hadoop that can run both operational applications and realtime analytics. It also allows IT departments to leverage their existing SQL/relational database expertise when working with Hadoop.
Splice Machine launched a public beta of its software in May and launched Release 1.0 in November with a management console, backup and restore capability, a cost-based optimizer, a native ODBC client, performance enhancements for the database engine and support for additional Hadoop platforms.

Trifacta v2
Big data can be messy. Trifacta attracted a lot of attention this year with its Trifacta Data Transformation Platform that uses visualization, machine learning and "predictive interaction" technology to "easily transform raw, complex data [in Hadoop] into clean and structured formats" for analysis. That, according to the company, makes it easier for businesses to derive real value from their data.
Trifacta launched the first release of its software in February, followed up with the 2.0 release in October that adds advanced data-profiling functions, the ability to leverage Hadoop's multiworkload processing capabilities, and native support for more complex data formats, including JSON, Avro, ORC and Parquet.