What You Missed At The Strata + Hadoop World Show

Big Data, Big News
San Jose, Calif., was the center of the big data and Hadoop universe this week as developers, vendors, resellers and users of leading-edge big data technology converged for the Strata + Hadoop World show.
Everything from the latest in business analytics applications, to tools for managing big data, to software to make Hadoop more secure were on display. One thing is clear: The big data arena is still one of the fastest-changing segments of the IT industry.
Here's a roundup of the biggest technology announcements at the show.
Altiscale Steps Up Hadoop Security With Kerberos Support
Given that Hadoop implementations often contain sensitive, personally identifiable information that's subject to regulatory controls, improving the security of Hadoop systems is becoming a priority for many IT organizations.
Altiscale, which provides Hadoop as a cloud service, is now offering Kerberos authentication as part of its Altiscale Data Cloud service. Kerberos leverages strong cryptography that protects against both outside attacks and malicious insider activity.
Altiscale's Kerberos authentication is currently in private beta testing and will be generally available this spring.
Attunity Replicate Enhances Hadoop Big Data Platforms
Information availability software developer Attunity has expanded its Attunity Replicate system with new functionality and use cases for Hadoop platforms. By reducing the time, labor and complexity involved in moving data into and out of Hadoop, Attunity said it hopes its software will accelerate Hadoop adoption.
Attunity Replicate is now optimized to better support data consolidation, data warehouse integration with Hadoop, and disaster recovery between data warehouses and backup targets, including Hadoop. The software also enables new access methods for HDFS and Hive, and is certified to work with MapR Technologies and Pivotal Hadoop distributions.
BlueTalon Boosts Hadoop Security With Policy Engine
BlueTalon is another company that's addressing Hadoop's security shortcomings. Specifically, it's working to resolve the problem of how to manage data access when departments, and even individuals, require different levels of authorization to view the same data.
The BlueTalon Policy Engine helps secure Hadoop clusters by enforcing granular data-centric access control policies and provisioning throughout an organization. The technology provides realtime data-access authorization at the row, column and even cell level at runtime for each query. The software safeguards data by developing, enforcing and auditing data-access policies.
Centrify Introduces Identity Management System For Hadoop
Centrify debuted the Centrify Server Suite 2015 that provides privileged identity management tools for big data infrastructures based on Apache Hadoop. The software allows IT organizations to leverage their existing Active Directory infrastructure to control access, manage privileges, address audit requirements and secure machine-to-machine communications within and across Hadoop clusters, nodes and services.
The release has new features and compatibility enhancements in Kerberos network authentication, service account management, and Active Directory and Hadoop interoperability.
Cloudera Gets Real-Time With Kafka
Cloudera has integrated Apache Kafka with its big data platforms, including its CDH distribution of Hadoop and Cloudera Enterprise. Kafka is an open-source, publish-subscribe messaging system that can ingest huge volumes of real-time streaming data.
The integration will allow businesses and IT organizations to build complete end-to-end workloads that incorporate components such as Apache Spark Streaming and Apache HBase within a single system. That, according to Cloudera, provides a high-performance system for ingesting new and varied data streams and exploring new data use cases.
Dataguise Security Software Protects NoSQL Databases Against Data Breaches
Dataguise showed off its recently launched DgSecure software, what the company calls the first data-centric discovery and security software to counter the risk of data breaches in NoSQL data stores.
DgSecure helps businesses locate, identify and manage sensitive data in NoSQL systems (such as social security or credit card numbers) and apply data-protection policies based on user permissions. The software also provides audit capabilities that help database administrators monitor who has access to sensitive data.
The first release of DgSecure supports Cassandra/DataStax NoSQL databases with support for HBASE, MongoDB and others to follow later in 2015.
Dato Updates Machine-Learning Platform, Embraces Hadoop And Spark Data
Dato has upgraded its GraphLab Create machine-learning platform with new capabilities that help data scientists work with terabytes of data to build intelligent applications. Machine learning is the development of software algorithms that can "learn" from data and help discover predictive insights from large, complex data sets.
New features in GraphLab Create include predictive service deployment enhancements and data science task automation. (Data science is the extraction of useful knowledge from data.)
Dato also announced that it will open-source its core engine technology and is offering new pricing and packaging options for its software.
Hewlett-Packard Adds Predictive Analytics To Its Haven Big Data Platform
Hewlett-Packard debuted HP Haven Predictive Analytics, a toolset the company said would accelerate and operationalize large-scale statistical analysis and machine-learning tasks.
HP Haven Predictive Analytics incorporates HP's Distributed R, a high-performance analytical engine based on the open-source R statistical programming language, and HP's Vertica analytical database.
HP is offering HP Haven Predictive Analytics as a free, open-source product.
IBM Expands Data Science Capabilities Of BigInsights For Apache Hadoop
IBM is adding in-Hadoop analytics technologies to its IBM BigInsights for Apache Hadoop software, including machine learning, support for the R programming language and other new features.
The software suite has three new modules: IBM BigInsights Analyst that includes the company's SQL engine, spreadsheet and visualization tools; IBM BigInsights Data Scientist with a new machine-learning engine and support for R statistical computing; and IBM BigInsights Enterprise Management, which provides tools to allocate resources and optimize workflows in Hadoop clusters.
MapR Technologies' Hadoop System Enables Realtime Big Data Apps
MapR Technologies launched version 4.1 of its Hadoop distribution that enables realtime, asynchronous replication through the use of MapR-DB table replication. The new functionality improves user and application access to realtime data for analysis and makes realtime disaster recovery possible.
MapR also unveiled three Quick Start Solutions that package the vendor's software: Data Warehouse Optimization and Analytics, Security Log Analytics, and Recommendation Engine.
Microsoft Expands Azure HDInsight's Ecosystem
Microsoft offered a preview of Azure HDInsight, the company's Apache Hadoop-based cloud service, running on Ubuntu Linux clusters. The move marks Microsoft's efforts to expand adoption of its cloud big data system beyond the Microsoft Windows realm.
Microsoft also announced the general availability of Storm on HDInsight. Apache Storm is an open-source, distributed computation system that processes streams of data in realtime. Microsoft also said its Azure Machine Learning system is now generally available.
Paxata Spring '15 Release Promises Improved Big Data Prep Features
The newest edition of Paxata's adaptive data preparation software offers a number of enhancements around performance, scalability, elasticity, efficiency and connectivity. The new features expand the technology's data preparation capabilities to handle massive volumes of data.
Paxata's software, which provides an alternative to building complex, expensive data warehouse systems, makes it possible to extract value from Hadoop environments without coding ETL (extract, transform, load) processes -- estimated to be 80 percent of MapReduce jobs, according to the company.
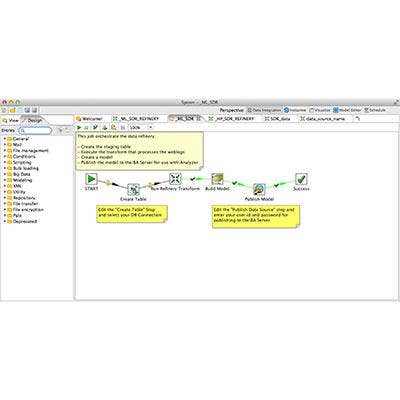
Pentaho Offers Links To Amazon Redshift And Cloudera Impala
Pentaho launched version 5.3 of its software suite, which opens its "data refinery" system to Amazon's Redshift cloud data warehouse and Cloudera's Impala massively parallel processing SQL query engine. The move will help Pentaho users take advantage of cloud-computing resources and more easily scale up.
Pentaho's data refinery transforms raw data into actionable information. The company said the NASDAQ exchange is using Pentaho in conjunction with Amazon Redshift.
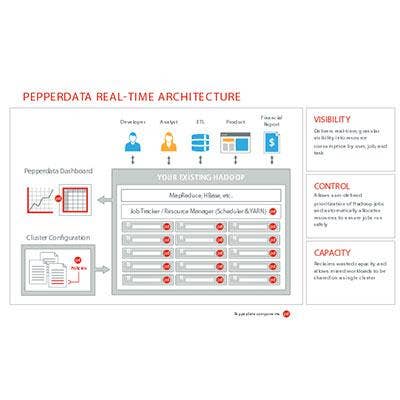
Pepperdata Software Optimizes Hadoop Performance
Pepperdata's real-time optimization software provides a new level of management and control for Hadoop clusters that many businesses need before they can rely on Hadoop for serious IT production tasks.
The software provides visibility into IT resources, including CPU, memory, disk input/output and network capacity, to help manage resource utilization, prevent bottlenecks that hinder performance, and meet service level agreements.
Pepperdata supports all Hadoop distributions, including those from Cloudera and Hortonworks.

Pivotal Moves To Open Source Components Of Its Big Data System
Pivotal debuted a new release of its Pivotal Big Data Suite and said it will release the core components of the product line as open-source projects, including the Pivotal Greenplum database, Pivotal GemFire in-memory database and Pivotal HAWQ SQL engine for Hadoop.
The latest release of the Pivotal Big Data Suite offers new entitlements for Pivotal Cloud Foundry, and new application services including Spring XD, Redis and RabbitMQ. Pivotal also announced that it would now offer the entire suite for a single subscription price.
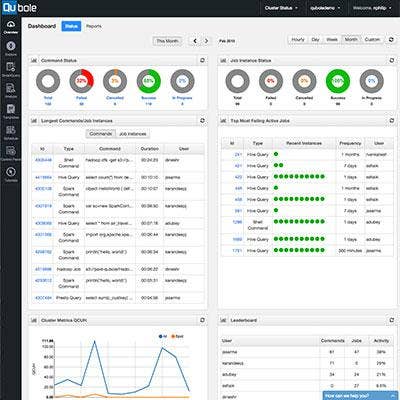
Qubole Adds Spark To Its Big Data-as-a-Service Platform
Qubole has added the Apache Spark processing engine to its Qubole Data Service (QDS) platform, the vendor's Hadoop-based cloud service. The addition of Spark will broaden the types of workloads that data scientists and analysts can run on QDS.
QDS runs on Amazon AWS, Google Compute Engine and Microsoft Azure, bringing big data capabilities to a wider audience by eliminating the complexities of on-premise Hadoop deployments.
Apache Spark is an in-memory processing engine that turbocharges Hadoop. The addition of Spark to QDS also will improve its ability to handle processing-intensive tasks such as machine learning and predictive analytics.
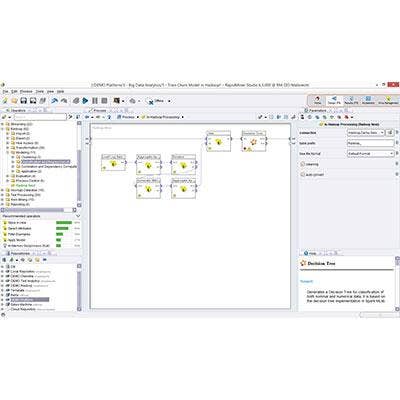
RapidMiner Updates Its Advanced Analytics Platform
RapidMiner's forte is its ability to push analytical computations down to big data in Hadoop rather than extracting data to build and score analytical models.
RapidMiner Radoop, the company's software for building and deploying predictive analytic models, is now integrated with machine-learning algorithms from MLib, the Apache Spark machine-learning library. That makes full use of the Spark processing engine in a Hadoop cluster and boosts performance by a factor of up to 20.
Radoop is also now integrated with Kerberos authentication security. Data security can slow down analytical processes, but the Kerberos integration helps eliminate that bottleneck. And the new release offers a guided approach to building analytical models -- based on the experience of the 250,000-member RapidMiner community -- and generates context-aware recommendations.
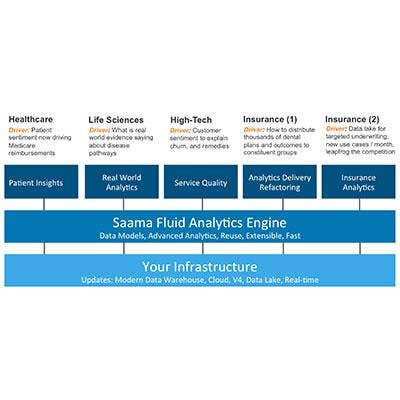
Saama Technologies Supports Data Science With Fluid Analytics Engine Debut
Saama Technologies launched its Fluid Analytics Engine, a system with more than 3,000 algorithms that support data science -- the extraction of useful knowledge from large volumes of data.
The Fluid Analytics Engine also includes a number of templates and visualization capabilities that aid in data science. The system supports Saama's existing suite of Ready Analytics applications and is designed to make use of cloud resources and Hadoop-based "data lakes." The ability to reuse data science outcomes is a key selling point of the software.
SAS Debuts Data Loader For Hadoop
Getting the most out of Hadoop requires secure access, simplified data integration and data quality. The new SAS Data Loader for Hadoop provides the tools businesses need to manage, transform, cleanse and prepare data that resides within Hadoop.
The new software is based on SAS' data quality and data-integration technology. It runs in a web browser and uses a wizard-based graphical user interface to streamline the design, orchestration and execution of complex data-transformation tasks inside Hadoop. That provides a way for businesses to overcome the shortage of people with advanced Hadoop skills.
Sisence Partners With Simba For ODBC Connectivity
Big data analytics software developer Sisense is now offering ODBC connectivity, thanks to an alliance with connectivity technology developer Simba Technologies. Sisense will add Simba's ODBC 3.8 driver to its business analytics tool suite, paving the way for users to connect their Sisense analytics to MongoDB data stores.
The move, according to the companies, will allow Sisense users to directly query MongoDB databases through SQL, and transform raw data into actionable dashboards and insights without tedious scripting or coding.
Skytree Boosts Automation Features Of Its Machine-Learning Platform
Skytree launched Skytree Infinity 15.1, a new release of the company's machine-learning software that automates a number of key data science tasks and brings machine-learning capabilities to a broader audience.
Infinity 15.1 has a new unified, project-based data scientist workspace for visually preparing, building, deploying and managing data models. The release also provides improved model management and governance through the use of self-documenting models and audit trails.
Syncsort's New DMX Release Speeds Apache Hadoop Adoption
Syncsort's new release of its DMX data-integration suite provides "design once, deploy anywhere" capabilities that make it easier to adopt the Apache Hadoop big data system.
The software has a new "intelligent execution layer" that decouples the user experience from the underlying Hadoop-processing technology, such as MapReduce, Apache Spark and Apache Tez. That allows developers to design data transformations that can be run on Hadoop, Linux, Windows or Unix, either on-premise or in the cloud. Large-scale data- transformation tasks are one of the most common Hadoop workloads.
The DMX decoupling feature helps prevent application obsolescence by making it possible to run data flows across multiple compute frameworks.
Tableau Develops Spark SQL Connector
Tableau Software has developed a direct connector to Spark SQL, a key component of the Apache Spark project, which the company said will provide businesses with more flexibility when performing big-data analysis.
Apache Spark is a processing engine that turbocharges Hadoop operations, and Spark SQL provides a SQL-like interface to Spark. With its new connector technology, Tableau is offering a way to access that Spark-to-Spark SQL link through Tableau's business-analytics and data-visualization applications.

Tamr Unveils New Data Unification Platform, Packaged Applications
Tamr introduced a new version of the company's scalable data unification platform that simplifies and speeds up the process of collecting data from multiple sources, and makes it available for analysts and downstream applications.
The system includes Tamr Catalog, a tool for centrally cataloging all metadata available in an enterprise; improvements in scalable data connections with enhanced support for Oracle, Hadoop and unstructured data; and the ability to enrich Excel or Google Sheets spreadsheets using unified data.
Tamr also unveiled data-unification packages for business analysts specifically targeting CDISC (clinical data interchange standards consortium) data and procurement data.
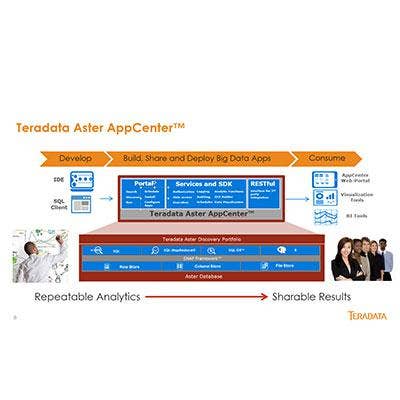
Teradata Launches Fleet Of Next-Gen Big Data Apps
Teradata debuted a series of self-service applications that run on the vendor's new Teradata Aster AppCenter platform. The new offerings make big-data analytics more accessible for typical business users, according to the company.
The applications cover a broad range of areas, including customer acquisition and retention, financial fraud detection, paths to purchase and marketing automation and some target-specific industries, such as the Path to Surgery health-care application that analyzes data and behavioral patterns that lead to major surgical procedures.
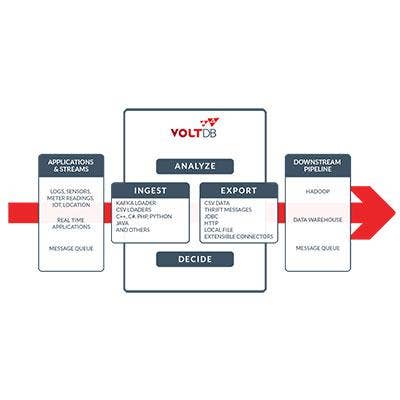
VoltDB Version 5.0 Targets Big Data And Internet-of-Things Applications
VoltDB demonstrated the latest release of its in-memory, scale-out operational database, which is designed to meet the growing demand for applications and analytical software on Hadoop that can handle streaming data. The nascent Internet-of-Things market is seen as increasing demand for systems that can handle more realtime data-processing tasks.
The new VoltDB release provides expanded SQL support and increased support for the Hadoop ecosystem, the latter through more data export connectors, including HDFS Export and Kafka Export, and a new Kafka Loader data import option. (Apache Kafka is an open-source, realtime messaging system.) Also new is the browser-based VoltDB Management Center for database monitoring and configuration management.