The 10 Coolest Big Data Products Of 2016 (So Far)

Hot Market, Cool Technology
Sales of big data and business analytics applications, tools and services hit nearly $122 billion last year and will grow more than 50 percent to $187 billion in 2019, according to market researcher IDC.
So it's no wonder that the conveyor belt of new big data products hitting the market, both from established companies and startups, continues unabated.
Here are 10 big data products that caught our attention in the first half of 2016. Some – but not all – of these made their debut at the Strata + Hadoop World conference in March or the Hadoop Summit in June.
(For more on the "coolest" of 2016, check out "CRN's Tech Midyear In Review.")
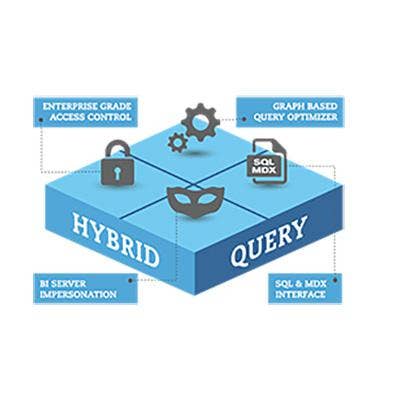
AtScale Intelligence Platform 4.0
AtScale develops software that provides a way for business users to access data in Hadoop clusters using applications and business analytics tools they already have and are familiar with, including Microsoft Excel, Tableau and QlikView.
AtScale Intelligence Platform 4.0, launched in March, offers what the company calls "hybrid query service," technology that can natively query Hadoop from any BI tool in either MDX or SQL – the two leading syntaxes for querying data in database systems.
The 4.0 edition also addresses security and data governance issues with "true delegation" technology that ensures that queries executed on Hadoop meet data governance and data access auditing policies.
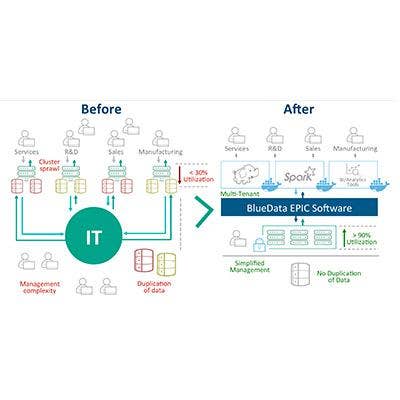
BlueData EPIC For Cloud Deployments
Big data projects often don't get beyond the pilot phase because of their complexity and cost. BlueData Software's EPIC platform is designed to make it easier to deploy Hadoop and Spark infrastructure and applications for development and production purposes.
Until recently, the enterprise edition of BlueData EPIC was available only for on-premise deployments. But in June, the company debuted BlueData EPIC for cloud deployments, what the company calls "Big Data as a Service."
BlueData Epic enterprise edition is now in what the company calls "directed availability" – available to a limited number of early adopter customers – on Amazon Web Services. General availability on AWS, as well as for Microsoft Azure, Google Cloud Platform and other public cloud services, will be in the coming months.
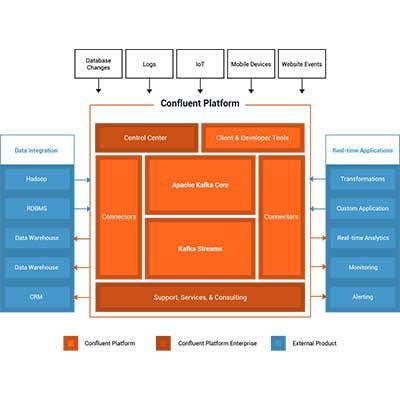
Confluent Platform 3.0
Working with live, streaming data is one of the biggest challenges in the big data arena. A key technology that's emerged to address the problem is Apache Kafka, an open-source message broker project that provides high-throughput, low-latency software for handling real-time data.
Confluent, launched in September 2014, was started by Kafka's original developers with the idea of leveraging the open-source software to help businesses realize value from streaming data. The Confluent Platform, built on Kafka, is a real-time data system that acts as a fault-tolerant, highly scalable messaging system. It can collect data from such sources as user activity logs, device instrumentation, stock ticker systems and other use cases.
In May, the startup debuted Confluent Platform 3.0, a major release that introduced Kafka Streams, which is a Java library for building distributed stream-processing applications. The 3.0 edition also features the Confluent Control Center, the company's first commercial product, for managing a Kafka environment.
Datameer 6.0 And Datameer Cloud
Datameer develops a big data analytics platform that provides users with self-service capabilities for data integration, preparation, analysis and visualization.
Datameer 6.0, which debuted in May, offers a new user interface and next-generation analytics workflow that the company said makes the data integration, preparation, analysis and visualization steps a single, fluid interactive process while improving data discovery.
The company also introduced Datameer Cloud, a cloud-based data preparation and analytics service running on Microsoft's Azure HDInsight and fully managed by Datameer.
DataStax Enterprise 5.0, OpsCenter 6.0 And Enterprise Graph
DataStax is a leading player in the NoSQL database arena, providing software based on the Apache Cassandra database for cloud and data-intensive applications.
The company has had a busy 2016. DataStax Enterprise (DSE) 5.0, launched in June, includes advanced replication capabilities that are particularly in demand for Internet of Things and retail applications. And it includes an updated version of Apache Spark for advanced search and analytics.
DSE Graph, unveiled in April and offered as an option for DSE, is a scalable real-time graph database for applications that need to manage complex data sets with many applications.
Also in June, the company debuted DataStax OpsCenter 6.0, a visual monitoring and management system for DSE that provides database monitoring, tuning, provisioning, backup and security capabilities.
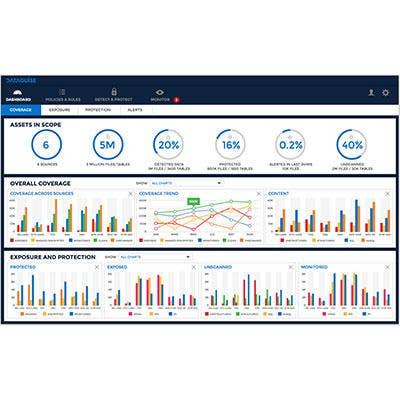
DGSecure 6.0
Dataguise develops data-centric security systems used to identify and protect an enterprise's most sensitive structured and unstructured data no matter where it resides, from traditional relational databases to big data stores like Hadoop.
DGSecure 6.0, unveiled in June, includes new features for data governance, privacy compliance and risk-mitigation tasks, including developing data security governance policies. The software includes a new dashboard for visual oversight of data breach risks and compliance with privacy policies.
Information Builders' WebFocus Business User Edition
Information Builders' WebFocus has long been the company's flagship business intelligence product. But the enterprise edition of the software has traditionally been oriented toward IT departments and developers that provide business intelligence reports for managers and workers.
The watchword in business analytics today is "self-service," providing users with big data tools they use to discover, prepare and analyze data themselves. In June, IBI announced the general availability of WebFocus Business User Edition (BUE), which lets non-technical users easily generate and share reports, dashboards and data visualizations without assistance from IT or BI developers.
The WebFocus BUE software includes the InfoAssist+ self-service analytics authoring tool for non-technical users, the BUE Portal for managing content and assembling analytics pages, and columnar storage for high-speed data discovery.
The browser-based software, which had a limited release earlier in the year, is designed for groups of 100 users.
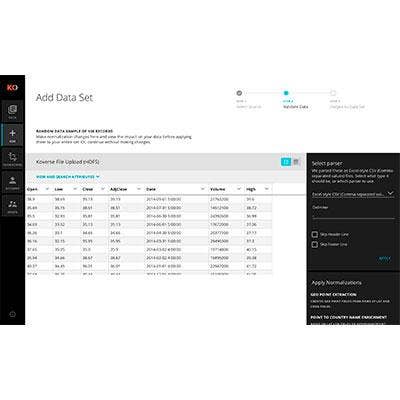
Koverse 2.0
Startup Koverse provides a "data lake-in-a-box" platform that makes it possible to collect big data and put it into production much more quickly and at a lower cost than with current technologies and practices.
The Seattle-based company was founded in 2012 and an early version of its technology debuted more than two years ago. The Koverse Platform 2.0, which just launched June 21, incorporates the Apache Accumulo "distributed key/value store" technology and the company's Universal Indexing Engine.
Koverse guarantees that it can bring a company's big data into production in a month or less – much faster than it took to build data warehouses in the past.
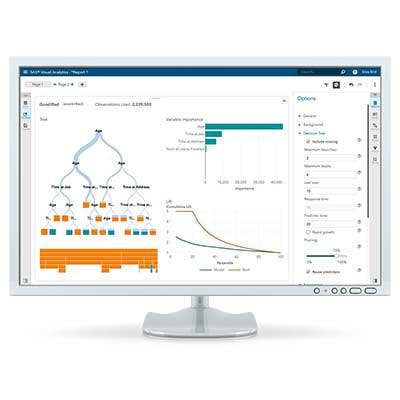
SAS Viya
Viya is a new analytics and visualization platform that can run in either private or public cloud environments. The next-generation software, which debuted in April, is SAS' first real push into the cloud and provides the foundation for SAS' future business analytics software.
The platform can be accessed using not only SAS' own programming language, but others including Python, Luya and Java, as well as supporting public REST APIs.
The software is currently available on an early-adopter basis and will be generally available sometime this quarter. Applications that SAS plans to provide this year for the Viya platform include SAS Visual Analytics, SAS Visual Statistics, SAS Visual Investigator and SAS Visual Data Mining and Machine Learning.
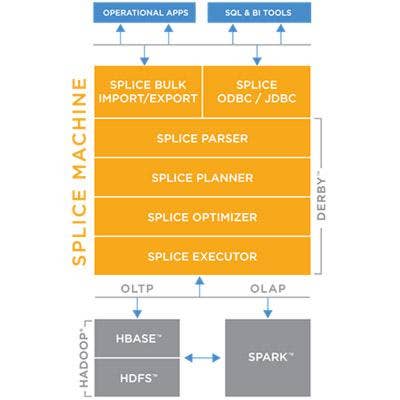
Splice Machine RDBMS Moves To Open Source
Splice Machine offers a database system that combines aspects of traditional relational database technology with the scalability of next-generation NoSQL databases and performance of in-memory systems. The database, which incorporates HBase, Hadoop and Spark technologies, can perform both transactional processing and business analysis tasks.
In June, Splice Machine took the bold step of making the database an open-source technology. Co-founder and CEO Monte Zweben said the goal of going open source is to attract more developers to the Splice Machine platform, who in turn will build more next-generation applications for the database.
Splice Machine will offer an open-source community edition of its software as well as an enterprise edition, with more features and functionality, for a license fee.