The 10 Coolest Big Data Products Of 2017 (So Far)

Hot Market, Cool Software
The volume of data being generated by e-commerce and online retail systems, mobile applications, social media and Internet of Things networks continues to explode. So it's no surprise the global market for big data products and services is expected to grow from nearly $29.7 billion last year to $66.8 billion in 2021, according to research firm MarketsandMarkets.
That growth is being fueled by a steady stream of new technologies – from both established companies and startups – for capturing, processing, managing and analyzing that data with the goal of developing business insights that give them a competitive edge.
Here are 10 big data products that caught our attention in the first half of 2017.
(For more on the "coolest" of 2017, check out "CRN's Tech Midyear In Review.")
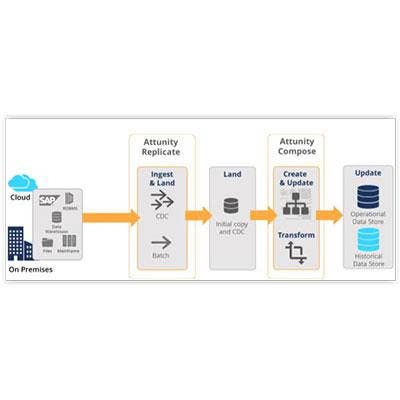
Attunity Compose For Hive
There has been significant growth in the number of organizations deploying Hadoop- and cloud-based data lakes in order to gain more value from their growing volumes of data. But building and maintaining data lakes can be a challenge.
In June Attunity, a developer of data integration and big data management software, debuted Attunity Compose for Hive, software that automates the process of creating and continuously loading operational and historical data for use with the Apache Hive open-source data warehouse software.
With Attunity Compose for Hive, data managers can improve the ROI of their data analytics efforts, ensure data consistency between source transactional systems and Hive, and utilize Hive's latest SQL capabilities.
Ayasdi Envision
Ayasdi develops a machine intelligence platform that businesses and organizations use to run big data applications.
Ayasdi Envision, which debuted in June, is a framework for developing intelligent applications that run on the Ayasdi platform and take advantage of its artificial intelligence and machine-learning capabilities.
Envision, according to the company, opens the intelligent application development and deployment process to a wider audience of knowledge workers and improves the usability of analytical workflows for users.
At the same time the company launched the Ayasdi Model Accelerator, a new intelligent application for developing models in the financial services industry.
Cloudera Altus
Businesses are increasingly turning to the cloud to run their data processing and analytics operations. In May big data platform developer Cloudera launched Cloudera Altus, a Platform-as-a-Service system for running large-scale data processing applications on a public cloud system.
The first available platform component is the Cloudera Altus Data Engineering service, which simplifies the development and deployment of elastic data pipelines used to provision data to Apache Spark, Apache Hive, Hive on Spark and MapReduce2 systems. Data engineers can run direct reads from and writes to cloud object storage systems without the need for data replication, ETL tools or changes to file formats.
Cloudera Altus is available on the Amazon Web Services platform with plans to support other public clouds including Microsoft Azure.
Databricks Runtime 3.0 With Structured Streaming
Databricks developed Structured Streaming, a high-level API that the company said enables stream processing at up to five times faster throughput than other engines. Structured Streaming makes it easier to develop end-to-end streaming applications that integrate with serving systems, data storage and batch processing jobs in a consistent and fault-tolerant way, according to Databricks.
The company introduced Structured Streaming in June as a new feature in Databricks Runtime 3.0, a core component of the Databricks cloud platform.
Databricks, founded by the developers of the Spark technology, also unveiled Databricks Serverless, a fully managed computing platform for Apache Spark that allows hundreds of users to share a single pool of computing resources. The company also debuted Deep Learning Pipelines for integrating and scaling out deep learning capabilities in Apache Spark.

DataStax Managed Cloud
In May DataStax unveiled DataStax Managed Cloud, a fully managed service of the DataStax Enterprise (DSE) data platform, which the company said reduces the amount of time businesses must spend on data management tasks and makes it easier to deliver cloud applications at scale.
Through the DataStax Managed Cloud, which like DSE is based on the Apache Cassandra NoSQL database, the vendor handles all data system administration, performance tuning, upgrades, backup and restore, and other tasks.
DataStax Managed Cloud is available on Amazon Web Services with plans to make it available on Microsoft Azure, Google Cloud Platform and other public cloud systems.

Hortonworks Dataflow 3.0
DataFlow is Hortonworks' "data-in-motion" platform that's used to collect, curate, analyze and act on data in real time across on-premises and cloud systems. The software is designed to help organizations tackle the growing volumes of streaming data from mobile devices, sensors and Internet of Things networks.
Hortonworks DataFlow 3.0, which debuted in June, provides new capabilities designed to make it easier for partners, ISVs and customers to develop streaming analytical applications – an increasingly important requirement for real-time analysis and Internet of Things applications.
HDF 3.0 introduced Streaming Analytics Manager, a toolset that allows application developers, business analysts and administrators to design, build, test and deploy streaming applications on HDF without coding. The new edition also includes a new repository of shared schemas that interact with data streaming engines including Apache Kafka, Apache Storm and Apache NiFi, providing improved data governance and operational efficiencies.
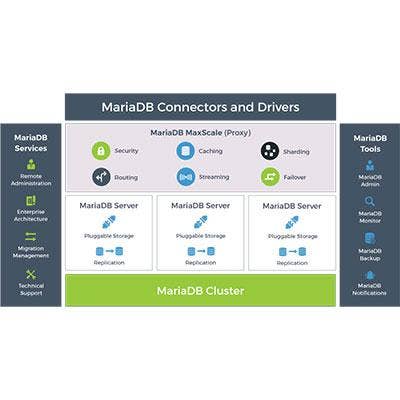
MariaDB TX 2.0
MariaDB, started by the people who developed the popular MySQL open-source database, develops the open-source MariaDB TX relational database that's designed for online transactional workloads. (The company also develops the MariaDB AX data warehouse system.)
MariaDB TX 2.0, released in May, includes the 10.2 edition of the MariaDB Server and MariaDB MaxScale 2.1 – the latter a database proxy system that extends the scalability, availability and security of the MariaDB Server while simplifying application development.
Key features in MariaDB TX 2.0 include JSON support for web, mobile and Internet of Things application development; data masking and result set limiting for improved security; support for Facebook's MyRocks transactional storage engine optimized for flash storage; and SQL compatibility with common table expressions and window functions.
Pepperdata Code Analyzer For Apache Spark
A growing number of businesses are implementing the Apache Spark engine to speed up their big data applications that work with increasingly large volumes of data. But the output of those systems often hinge on the effectiveness of the application doing the work. Lousy application code can result in poor results.
In May Pepperdata, which provides DevOps technology for the big data arena, launched Pepperdata Code Analyzer for Apache Spark, a tool that helps programmers developing Spark applications to identify performance issues. Developers can measure how Spark cluster resources such as CPU, memory, network and disk input/output are consumed by particular blocks of code. That and other capabilities help developers identify the code that's causing performance problems.
In March Pepperdata unveiled Pepperdata Application Profiler, a tool that provides Hadoop and Spark developers with recommendations for improving application job performance.

Qubole Data Service Enterprise And Community Editions
Accelerating the move of big data systems to the cloud, Qubole, a big data-as-a-service provider, unveiled three new products in May that the company said provide an autonomous data platform with intelligent automation that addresses the difficulty enterprises have in scaling their big data initiatives.
Qubole Data Service (QDS) Enterprise Edition self-manages, self-optimizes and learns by monitoring platform usage, analyzing metadata and applying machine learning and artificial intelligence to create alerts, insight and recommendations. The system runs on Amazon Web Services, Microsoft Azure and Google Cloud Platform.
In addition to QDS Enterprise Edition, Qubole debuted a free QDS Community Edition targeted at developers. Also new is QDS Cloud Agents, add-ons for QDS Enterprise Edition, that execute a range of data management chores to reduce costs and free up data professionals for other tasks.

Snowflake Computing Data Sharing
Snowflake Computing developed Snowflake Data Sharing, an extension of the company's cloud-based data warehousing service that allows subscribers to securely share live data among themselves.
Sharing data generally involves complex data transfer processes between multiple databases, FTP files and other routes. With Snowflake's new service capabilities, which it calls "data sharehousing," enterprises that use the Snowflake data warehouse service can establish one-to-one, one-to-many and many-to-many data sharing relationships.
With the data sharing service a company can link data silos across multiple business units to get a comprehensive view of the company's operations, according to Snowflake, or share data with its customers, partners and suppliers to reduce costs and improve efficiencies. SaaS business-to-business companies could use the service to aggregate customer data and provide it back as an analytical service, Snowflake said.