The 10 Coolest Big Data Products Of 2012

Big Data Is A Big Deal
"Big data" went from early-adopter buzzword to full-blown industry trend -- or even an entire industry by itself -- in 2012, judging by the number of big data products that spilled out of startups and established IT vendors alike. A sure sign of maturing big data technology was the number of significant "2.0" releases this year from such companies as Datameer, DataStax, Hadapt, Karmasphere and MapR Technologies.
Market researcher Gartner calculated that big data would drive $28 billion of IT spending in 2012. Not surprising, given that the exploding volume of information stored in the world's IT systems reached an estimated 2.7 zettabytes (that's 2.7 billion terabytes) in 2012 and the need for technology to collect, store, manage and analyze all that information is very real.
Here's our list of what we think were the coolest big data products to hit the market in 2012.
10. Dataguise DgHadoop
Complying with data privacy regulations can be a major challenge because Hadoop collects data from a wide range of sources, not just corporate databases. And, concentrating so much disparate data in one system increases the risk of data theft or accidental disclosure.
Dataguise launched in June what it described as the industry's first enterprise-grade data privacy protection and risk assessment application for Hadoop. The DgHadoop software provides compliance assessment and enforcement for centralized data privacy protection in order to meet privacy compliance regulations and reduce regulatory compliance costs.
9. Cloudera Impala
With its distribution of Apache Hadoop and related technologies and services, Cloudera is perhaps the most established of the big data companies. But that's not stopping it from developing some pretty cool stuff.
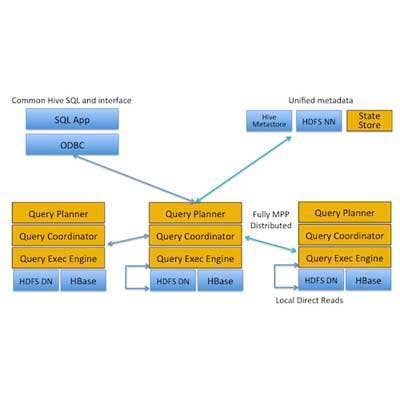
In October Cloudera released a real-time query engine for Hadoop called Impala that allows Cloudera Enterprise, the company's platform for managing massive amounts of data, to perform both real-time and batch operations on any type of structured or unstructured data. Impala manages data stored in the Hadoop Distributed File System (HDFS) and Hbase database. And the new Cloudera Enterprise RTQ (Real-Time Query) software provides the tools needed to manage Cloudera Impala in production environments.
In June Cloudera released the 4.0 version of Cloudera Enterprise. And in December the company raised $65 million in venture funding to help it expand and continue its product development efforts.
8. Hortonworks Data Platform 1.0
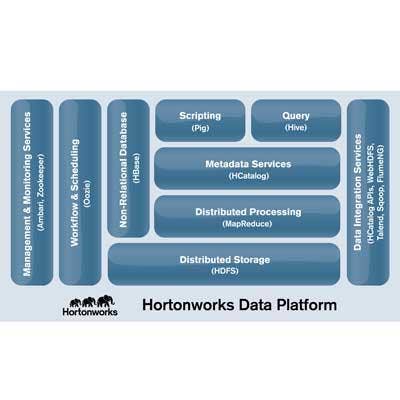
In the year since its June 2011 debut, Hortonworks offered a number of preview releases of the Hortonworks Data Platform (HDP), the company's distribution of the Apache Hadoop platform. But in June of this year, the startup announced the general availability of the long-awaited 1.0 release of the software.
Hadoop was a hot item in 2012, but it's an open-source product that's notoriously difficult to work with. Hortonworks wraps Hadoop with its own data management infrastructure; management, monitoring, metadata and data integration services; and the kind of customer support that businesses expect with commercial software.
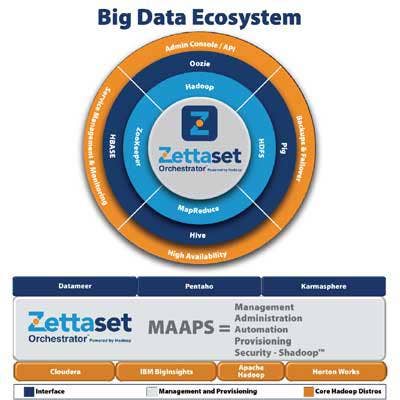
7. Zettaset Orchestrator v5
Zettaset Orchestrator automates the installation and management of Hadoop. Earlier this year at the RSA conference Zettaset outlined an initiative (under the wonderful name "SHadoop" for Secure Hadoop) to address security gaps and vulnerabilities that the company said exists in all distributions of the open-source Apache Hadoop.
Orchestrator v5 provides new access control, policy management, compliance and risk management capabilities to improve Hadoop cluster security and manageability. The software supports Lightweight Directory Access Protocol (LDAP) and Active Directory standards; provides centralized configuration management, logging and auditing tools; and role-based control to improve user authentication and access.
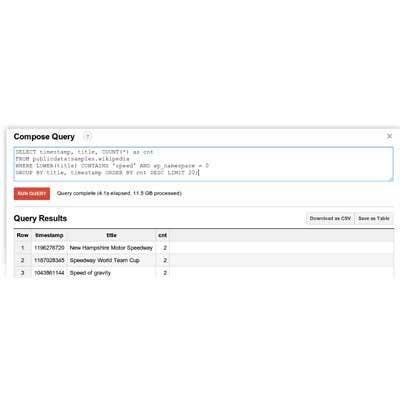
6. Google BigQuery
Taking advantage of its core competency of processing humongous volumes of data, Google launched Google BigQuery, cloud software that businesses can use to analyze data in real time.
Google introduced a test version of the service for developers in November 2011, based on the technology the company uses to examine its own data. In May it began offering it to the general public, providing it for free for storing and querying up to 100 GB of data. After that the company is charging 12 cents per GB for up to 2 TB of storage and 3.5 cents per GB for analysis.
5. Mortar Data
Working with Hadoop requires a fair amount of technical expertise. Mortar Data offers a cloud-based service, based on the Python programming language and Apache Pig technology for analyzing huge data sets, which makes Hadoop accessible to a wider audience of programmers.
Mortar Data emerged from stealth mode this spring and the New York company's long-range plan is to work with technology partners to bring a range of business intelligence, analytics and advanced monitoring capabilities to the Mortar Data platform.
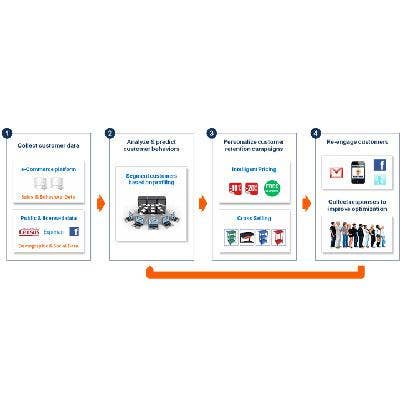
4. Retention Science
Founded in 2011 and officially launched in July, Retention Science developed what it calls the "Customer Profiling Engine," a big data marketing platform that helps online businesses analyze huge volumes of data to build customer loyalty and prevent customer churn.
The startup's applications help e-commerce companies predict how price-sensitive customers are and develop promotions accordingly, to identify where customers are in their "lifecycle" relationship with a business and create retention strategies, and to develop incentives for customers who are active on social networks. The Santa Monica, Calif.-based company is allied with MuckerLab, a Los Angeles technology incubator company.
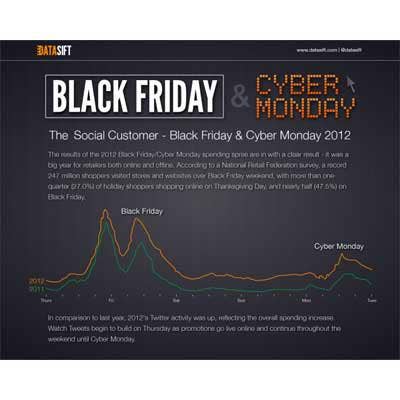
3. DataSift
We're cheating a bit here because DataSift officially launched its product at the end of 2011. But everyone really took notice this year of the company's software for capturing and analyzing the fire hose of data generated by social network sites like Twitter and Facebook.
DataSift offers software that businesses use to define complex filters, based on such criteria as location, gender and even sentiment, to sort through billions of social interactions. This year the San Francisco-based company inked a deal with Twitter, giving DataSift access to an archive of tweets going back to January 2010 for market research purposes. And in September, it launched a product specifically for the financial services industry.
2. Qubole
Qubole is developing what it calls an "auto-scaling" platform for analyzing and processing big data. The company's goal is to offer cloud-based Hadoop and Hive services that handle all infrastructure complexities behind the scenes, eliminating the need for businesses to architect, deploy and manage their own Hadoop clusters. That will free up developers and analysts to focus on developing queries and analyzing data.
The technology isn't generally available yet: Mountain View, Calif.-based Qubole exited stealth mode in June and is recruiting businesses and data scientists to participate in an early access program for its technology.
The company's founders, Ashish Thusoo and Joydeep Sen Sarma, helped build Facebook's data infrastructure and were contributors to the development of Hadoop. They also created Apache Hive, an open-source data warehouse system.
1. Platfora
Startup Platfora, which had been in stealth mode until October, unveiled its in-memory business intelligence software that can directly analyze data in Hadoop without the need for building a complex (and expensive) data warehouse or traditional data store. "This is really the beginning of the end of the data warehouse," said Platfora founder and CEO Ben Werther in an interview.
That's a pretty bold claim. But, Platfora just might revolutionize how big data is managed for analytical purposes. The company's software turns raw data in Hadoop into interactive, in-memory business intelligence for use in visualizations, dashboards and exploratory analytics. It supports all Hadoop distributions, including Cloudera, Hortonworks, MapR and Amazon Web Services.