CRN’s 2020 Products Of The Year
CRN editors compiled the top partner-friendly products and services that launched over the past year, then turned to solution providers to choose the winners.

The Best Of The Best
CRN’s Products of the Year awards for 2020 honor the very best partner-friendly products and services that launched over the past year—as chosen by solution providers themselves. To get things started, our editors selected product finalists in 23 key technology categories for the IT channel among offerings from September 2019 to September 2020. The categories ranged from big data, to cloud infrastructure and collaboration, to security, servers and storage. We then asked solution providers to choose winners based on how the products rate on technology, revenue and profit opportunities, and customer demand.
The survey received more than 5,000 product ratings from solution providers, and the product receiving the highest overall score in each category was named the winner. Notably, several companies took home multiple top prizes in this year’s contest: Cisco (with three category wins) and Hewlett Packard Enterprise, Microsoft and Lenovo (with two category wins each).
What follows are the winners and finalists in CRN’s Products of the Year awards for 2020.
BIG DATA
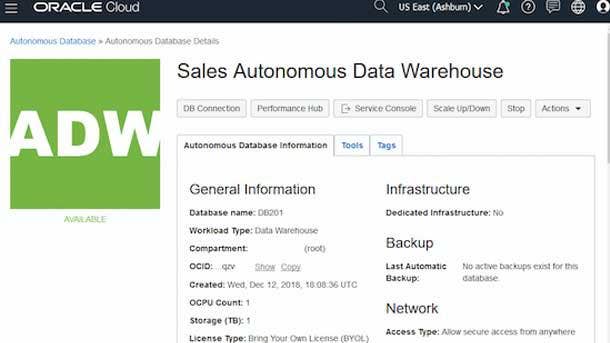
ORACLE AUTONOMOUS DATABASE
WINNER: OVERALL
With its fast-growing Autonomous Database offering, Oracle has said it has the makings for replicating the success of its original Oracle commercial relational database that launched the entire business. Autonomous Database, which automates the provisioning, configuration and scaling of databases, runs natively on the Oracle Cloud Infrastructure platform, and comes with capabilities such as automated data protection and self-repair after user errors and system failures. Recent enhancements aimed at taking Autonomous Database to the next level have included the introduction of a dedicated deployment option to provide operational control, reliability and security for all classes of database workloads. Oracle has also updated its Enterprise Manager platform to expand Autonomous Database support, including with guided migrations and a streamlined user experience for moving workloads from on-premises environments to Oracle Autonomous Database.
Subcategory Winner—Revenue and Profit: Couchbase Cloud
Couchbase Cloud is the next-generation database from Couchbase, available as a fully managed Database-as-a-Service running on Amazon Web Services. The offering is based on the Couchbase Server, a multipurpose NoSQL database that combines a high-performance, memory-first, globally replicating cluster architecture with key-value stores, a SQL-compatible query language and a schema-flexible JSON format.
Finalist: MariaDB SkySQL Database-as-a-Service
Earlier this year, MariaDB launched the cloud-based MariaDB SkySQL Database-as-a-Service for both transactional and business analytics applications. The company recently expanded the functionality of the offering by adding the ability to customize database options and configurations as a way to meet requirements for security, high availability and disaster recovery.
Finalist: Snowflake Cloud Data Platform
The Snowflake Cloud Data Platform provides a centralized place for deriving business insight from big data via a data warehouse that was created for the cloud along with secure access to an entire network of data and a core architecture to support versatile data workloads. Recent updates to the Snowflake Cloud Data Platform include the new Snowsight analyst experience for executing queries and commands against Snowflake.
Finalist: Splunk Data Stream Processor
Splunk’s Data Stream Processor rapidly collects and processes data before delivering it to Splunk systems, as well as other platforms, in real time. Benefits include the ability to transform raw data into high-value data prior to sending it elsewhere, along with data protection capabilities through masking sensitive data.
BUSINESS INTELLIGENCE AND ANALYTICS
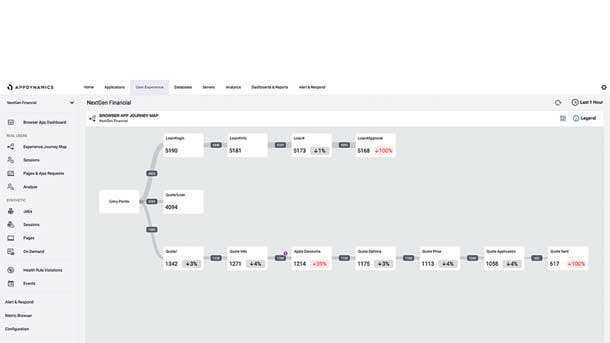
CISCO APPDYNAMICS
WINNER: OVERALL
Cisco Systems has reported a dramatic increase in business through the channel for its AppDynamics monitoring software, even as the company has continued to enhance the software with new capabilities including increased visibility into the paths of applications. AppDynamics brings together application performance monitoring with monitoring of business performance and end users, which translates into key business analytics and actionable insight for customers. Cisco has augmented the usefulness of the platform with updates such as the introduction of the AppDynamics Experience Journey Map, a new view that provides users or partners with visibility into the path of an application using data science algorithms that can pull out information in real time. The map shows user flows overlaid with performance and business metrics, which enable the identification of problems such as application bottlenecks.
Finalist: Microsoft Power BI
With Power BI, Microsoft offers an array of business intelligence and analytics capabilities including a simplified way to connect to and visualize data, paired with the ability to gain insight from the data using analytics. Power BI also enables groups to easily collaborate together on the same data and share insight across Microsoft applications such as Teams and Excel.
Finalist: SAP Business Technology Platform
SAP has continued to build out the capabilities of its Business Technology Platform with a number of recent additions and enhancements to the portfolio of integrated products. Additions to the Business Technology Platform have included SAP HANA 2.0 SPS 05, a new release of SAP HANA that supports hybrid environments and enhanced native storage extensions for simplifying data management.
Finalist: Splunk Cloud
Recent updates to Splunk Cloud—the company’s cloud-based machine data platform service—include the ability to run the service on the Google Cloud, joining Amazon Web Services. Key benefits include real-time visibility across Google Cloud events, logs, performance metrics and billing data, as well as performance monitoring for Google Cloud Services with Splunk’s SignalFX platform.
Finalist: Tableau
The recent debut of Tableau 2020.3 added capabilities for outputting to and updating external databases directly from the Tableau Prep Builder tool—which enables Tableau to meet a wider number of data preparation needs—as well as the introduction of new Tableau administrator tools that simplify the distribution of product licenses.

COLLABORATION
MICROSOFT TEAMS
WINNER: OVERALL
Microsoft has pushed a rapid pace of development for the Teams collaboration app as users have surged in 2020. In particular, Teams has received a series of major upgrades around its video meeting capabilities—such as with a larger gallery view and the ability to pop out separate windows for meetings in the app. Microsoft is also aiming to make one of the newest Teams features into the next big game-changer for videoconferencing. Together Mode places participants into a shared virtual background, which helps people to feel more like they’re sitting in the same room—and more capable of picking up nonverbal cues. Microsoft has also tackled personal productivity within Teams, such as with the tasks app. The app offers a unified view within Teams of tasks across different apps, including Planner, Microsoft To Do and Outlook.
Subcategory Winner—Revenue and Profit: RingCentral
Recent RingCentral updates have included the launch of RingCentral Video, which integrates video chat with RingCentral’s UCaaS platform—providing a comprehensive messaging, video and phone offering for businesses of all sizes. RingCentral enables users to easily switch between methods of communication without leaving the app, and the app can be accessed from any browser without the need to download it.
Finalist: Cisco Webex
Cisco’s WebEx collaboration platform has featured enhancements such as the launch last year of the Webex Teams unified app. The app brings together calling, meetings, messaging and video device control—providing customers with a consistent experience regardless of how they join. Other recent updates to Webex have included new grid views, virtual backgrounds and blurring for backgrounds.
Finalist: Intermedia Unite
Intermedia Unite, which brings together a PBX phone system with chat, videoconferencing, file sharing and backup, provides its Unified-Communications-as-a-Service offering with simplified management capabilities and strong reliability. Intermedia recently brought Contact Center as a Service to Unite as an integrated feature for the platform.
Finalist: Nextiva
With its Cospace solution, Nextiva is helping businesses navigate the shift to remote work. Nextiva Cospace features HD voice and video, task management, file sharing, calendar management and chat—all designed with a simplified and user-friendly interface. Capabilities include video and audio meetings with up to 250 participants.
Finalist: Zoom
Along with its widely used videoconferencing application, Zoom has launched a cloud phone system, Zoom Phone, as an add-on to the video platform. Zoom Phone supports inbound and outbound calling through the public switched telephone network, and offers integrated telephony features that enable customers to replace their existing PBX solution.

CRM/ERP
SALESFORCE
WINNER: OVERALL
Salesforce’s market dominance in CRM software has continued as the company has kept the innovation going strong on its unified platform, Customer 360, which spans sales, marketing, service and more. In the realm of AI advances, Salesforce has been continually augmenting its Einstein intelligence layer to the point that Einstein’s capabilities are now pervasive across Salesforce’s offerings. Recent updates to Einstein have focused on improving sales productivity, including through the launch of Einstein Reply Recommendations, which leverages natural language processing to provide immediate suggestions about ideal responses to customer inquiries. Meanwhile, another new feature, Einstein Next Best Action,
uses predictive technologies and business rules to recommend a course of action that might reveal cross-sell opportunities and boost customer satisfaction
Finalist: Microsoft Dynamics 365
Dynamics 365, which is Microsoft’s cloud-based platform combining CRM and ERP, offers advantages such as bringing all business and customer data into one location for enhanced visibility and business insight. Recent additions included Dynamics 365 Customer Voice for improving customer responses and new account protection and loss prevention capabilities for Dynamics 365 Fraud Protection.
Finalist: Oracle NetSuite
Recent updates to Oracle’s NetSuite—which combines ERP with CRM and other business software—include invoice grouping (which lets users consolidate multiple invoices into one invoice for the customer); improvements for bank reconciliations (with new capabilities to create and post transactions automatically); and automated posting of cross-charge transactions between an organization’s subsidiaries.
Finalist: SAP S/4HANA
SAP has been transitioning its product portfolio from its traditional on-premises ERP applications to cloud-based applications, including SAP S/4HANA—an “intelligent ERP system” featuring embedded AI technologies that enable enhanced performance and business insight. To help give customers confidence about moving to the cloud, SAP earlier this year announced a commitment to provide maintenance for SAP S/4HANA until 2040.
Finalist: ServiceNow Customer Service Management
The ServiceNow Customer Service Management application helps companies resolve issues end to end, proactively fix customer problems and drive actions to instantly take care of customer requests. ServiceNow enables users to deliver strong customer experience and increase efficiency by combining engagement capabilities with service management and operational abilities for monitoring, diagnosing and proactively resolving issues.

HYBRID CLOUD
AWS OUTPOSTS
WINNER: OVERALL
Amazon Web Services, the largest public cloud platform by market share, brought its on-premises version of its public cloud into general availability last December with the launch of AWS Outposts. The offering entails AWS installing and managing a server rack in its customers’ data centers, and addresses the needs of enterprises that must keep applications close to home. Outposts launched with AWS EC2 instances and EBS block storage, as well as two hosted container services, ECS and EKS. S3 storage on AWS Outposts became available in September. The first variant of Outposts is the “AWS native” option for customers that want to use the AWS APIs and control plane alongside their deployments in AWS regions. A second variant of AWS Outposts, for customers that want to use a VMware control plane, is expected in 2020.
Subcategory Winner—Customer Demand: VMware Cloud on AWS
Among the recent changes to VMware Cloud on AWS is a reduction in the minimum size of a deployment, and availability of a storage-optimized AWS EC2 instance—both of which make it easier for partners to sell the service to smaller customers. The changes have also included the ability to deploy and manage VMware Cloud on AWS instances with vCloud Director.
Finalist: Dell Technologies Cloud
Recent enhancements to the Dell Technologies Cloud have included the addition of a direct path to Kubernetes container orchestration from a single environment with support for containerized workloads and traditional virtual machines on the same VxRail infrastructure. The Dell Technologies Cloud also extended its networking capabilities with new updates from the Dell EMC SD-WAN Solution powered by VMware.
Finalist: HPE GreenLake Cloud Services
With GreenLake Cloud Services, Hewlett Packard Enterprise provides pay-per-use, self-service and scalability for applications and data regardless of whether they’re located on-premises, in colocation or at the edge. The offering covers everything from container management, storage and virtual machines to networking, compute and data protection while also providing pre-integrated building blocks as well as a choice of configurations for its services.
Finalist: Lenovo TruScale Infrastructure Services
Lenovo TruScale Infrastructure Services is a pay-per-use subscription offering for Lenovo data center products based on electrical consumption, which allows customers to use and pay for on-premises data center hardware and services without having to purchase the equipment. Customers never take capital ownership of the hardware or other IT assets, and there is no minimum capacity requirement for TruScale.

HYPERCONVERGED INFRASTRUCTURE
CISCO HYPERFLEX
WINNER: OVERALL
Built on Cisco’s UCS server portfolio, Cisco’s HyperFlex hyperconverged infrastructure system enables the benefits of cloud (such as agility and a pay-as-you-go model) while also supporting distributed computing across multiple sites. HyperFlex leverages data optimization technologies and integrated fabric networking to help enable many types of workloads and offers configuration options such as all-flash, all-NVMe, hybrid and edge. Key capabilities include comprehensive management via the Cisco Intersight platform, while recent updates have included the launch of the HyperFlex Application Platform.The platform enhances the combination of HyperFlex systems with Kubernetes container orchestration, addressing the issue of how to provide persistent storage to containers.
Subcategory Winner—Technology: HPE SimpliVity
Hewlett Packard Enterprise has upped its hyperconverged price/performance game by outfitting SimpliVity with AMD’s EPYC Rome processors. The updates are targeted at serving the virtual desktop infrastructure markets including work-at-home and medical and emergency services. HPE also recently added its AI InfoSight predictive analytics software to HPE SimpliVity.
Finalist: Dell Technologies VxRail
For the first time, VxRail has been equipped with AMD-based processors with the recent launch of Dell Technologies VxRail E-Series. The new VxRail E-Series includes second-generation AMD EPYC professors that offer customers up to 64 high-performance cores and support for PCIe 4.
Finalist: Nutanix HCI
Nutanix HCI is composed of its software stack, which includes software-defined storage, AOS; an infrastructure control plane, Prism; and its AHV hypervisor. In June, Nutanix added Foundation Central to allow IT teams to deploy private cloud infrastructure on a global scale from a single interface, new life-cycle management features, as well as Nutanix Insights to provide predictive health and automated support services to help streamline operations.
Finalist: Scale Computing HC3
With HC3, Scale Computing offers a highly available and fully integrated offering for running applications that replaces traditional virtualization software, servers, disaster recovery software and shared storage. Scale Computing leverages its patented HyperCore technology to provide self-healing capabilities that identify and fix infrastructure problems in real time—ultimately providing maximum uptime for applications.

INDUSTRY-STANDARD SERVERS
HPE PROLIANT MICROSERVER GEN10 PLUS
WINNER: OVERALL
With the HPE ProLiant MicroServer Gen10 Plus, Hewlett Packard Enterprise has combined powerful performance, security and management capabilities for partners—all in a compact and lightweight form factor. The server offering has been designed to meet the needs of small and midsize businesses—and the channel partners that serve them—even though it boasts technologies that are fundamentally enterprise-grade. The HPE ProLiant MicroServer Gen10 Plus has a size similar to a textbook and a weight of just 10 pounds, making it about onethird of the size of existing server offerings in the market. But it still can offer up to twice the performance of its predecessor server, with options for Intel Xeon E processors or less expensive Pentium chips. On security, for the first time on a ProLiant MicroServer, the offering includes HPE’s silicon root of trust technology that protects the system down to the firmware. And in terms of management, HPE’s InfoSight for Servers—an AIpowered management tool that provides predictive analytics— is made available for the first time to SMBs with the offering. Meanwhile, the ProLiant MicroServer Gen10 Plus comes equipped with remote management capabilities via HPE’s Integrated Lights Out (iLO) technology for the first time.
Finalist: Dell EMC PowerEdge XE2420
The Dell EMC PowerEdge XE2420 is a highly configurable, dual-socket 2U rack server featuring two second-generation Intel Xeon Scalable processors, with further performance coming from up to four Nvidia acceleration cards. For use at the edge, the PowerEdge XE2420 can leverage the Integrated Dell Remote Access Controller 9 with the optional data center capability to provide streaming telemetry. And for harsh environments, the server is rated at temperatures between 41 degrees and 104 degrees Fahrenheit.
Finalist: IBM Bare Metal Servers
IBM Cloud recently enhanced its IBM Bare Metal Server line with the addition of second-generation AMD EPYC processors. The latest versions for IBM Cloud users include up to 96 CPU cores per platform, up to 4 TB of memory, up to 24 local storage drives, and the choice of Red Hat Enterprise Linux, CentOS, Ubuntu or Microsoft Windows Server.
Finalist: Lenovo ThinkSystem SR860/SR850 V2
Lenovo’s SR860 V2 and SR850 V2 feature third-generation Intel Xeon Scalable processors with enhanced support for SAP HANA based on Intel Optane persistent memory 200 series, and can be configured with up to 48 2.5-inch storage drives. The ThinkSystem SR860 V2 server also supports four double-wide 300W or eight single-wide GPUs for handling artificial intelligence workloads, virtual desktop infrastructure or data analytics.
Finalist: Supermicro Nvidia A100 GPU-Powered Systems
Supermicro’s Nvidia A100 GPU-Powered Systemssupport up to eight Nvidia A100 PCIe GPUs via direct-attach PCIe 4.0 in conjunction with dual AMD EPYC 7002 processors. They can be configured with up to 8 TB of ECC DDR4 3,200MHz SDRAM and up to 24 hot-swap 2.5-inch storage devices and up to four 2.5-inch NVMe drives. There are nine or 10 PCIe 4.0 slots, depending on whether NVMe devices are used.

INTERNET OF THINGS
SCALE COMPUTING HE150
WINNER: OVERALL
Last December, Scale Computing launched its HE150 hyperconverged infrastructure offering as a way to provide the benefits of its HC3 virtualization platform but in a compact form factor and with high availability for use in edge environments. The HE150, which offers all-flash, NVMe storage-based compute, does not require a server closet or rack and takes up about the same amount of space as a stack of three smartphones. The appliance leverages Intel NUC mini PCs rather than traditional 1U servers, and includes disaster recovery and integrated data protection capabilities as well as rolling upgrades and high-availability clustering. The HE150 ultimately provides improved availability and power efficiency compared with 1U servers in edge environments, making it an ideal offering for smaller workload requirements at the edge.
Subcategory Winner—Revenue and Profit: Nvidia Jetson Xavier NX
Nvidia said its recently launched Jetson Xavier NX is the world’s smallest supercomputer for artificial intelligence applications at the edge, giving robotics and embedded computing companies the ability to deliver server-class performance in a 10-watt power envelope. The computing board measures just 70 x 45mm, and comes with 384 CUDA cores and 48 tensor cores, allowing it to deliver up to 21 Tera Operations Per Second. (Note: Nvidia Jetson Xavier NX also tied with Scale Computing HE150 as the Subcategory Winner for Technology.)
Finalist: APC by Schneider Electric - 6U Wall Mount EcoStruxure Micro Data Center
The 6U Wall Mount EcoStruxure Micro Data Center from APC by Schneider Electric is an edge computing offering that delivers high resiliency with a compact footprint. The micro data center enables deployment of server and networking equipment at the edge without taking up any floor space, as it only extends 14 inches off the wall. Advanced security options include camera monitoring, keylock doors and intrusion detection.
Finalist: AWS Snowcone
AWS Snowcone is a compact, 4.5-pound, portable and rugged edge computing device for collecting, processing and transferring data to the Amazon Web Services cloud from disconnected environments outside traditional data centers. The offering includes support for AWS IoT Greengrass, the ability to run Amazon Elastic Compute Cloud (EC2) instances and local storage.
Finalist: Eaton MiniRaQ
The Eaton MiniRaQ is a vertical wall-mount rack enclosure for edge IT and power management equipment that’s capable of safely mounting equipment up to 35 inches in length--and supports up to 400 pounds. The system features a compact footprint for fitting into confined spaces, and the MiniRaQ is also compatible with a variety of Eaton UPS systems.

MULTIFUNCTION PRINTERS
XEROX ALTALINK C8170
WINNER: OVERALL
Part of its new AltaLink C8100 series of multifunction printers (MFPs), Xerox’s AltaLink C8170 enhances productivity with the ability to use an array of on-device apps and with advanced capabilities such as ultrafast scanning. The color MFP enables scanning documents at up to 270 images per minute, with print speeds of up to 70 pages per minute. With the inclusion of Xerox’s ConnectKey app interface,the AltaLink C8170 can access cloud services such as Microsoft Office 365, Dropbox and Google Drive, as well as numerous other apps. Xerox’s own apps, meanwhile, provide unique functionality such as translating copy into more than 50 languages (with the Xerox Translate and Print app); turning handwritten notes into digital (with the Xerox Note Converter app); and converting hard copy to audio (using the Xerox Audio Documents app).
Subcategory Winner—Technology (tied with Xerox): HP LaserJet Enterprise MFP M635h
Along with top print security features such as self-healing Sure Start capabilities, HP’s LaserJet Enterprise MFP M635h enables users to print two-sided documents nearly as fast as single-sided. The multifunction printer offers print speeds of up to 65 pages per minute and scanning speeds of up to 75 pages per minute.
Finalist: Canon ImageRunner Advance DX C3730i
Key features of Canon’s ImageRunner Advance DX C3730i include a new document feeder offering a 200-sheet capacity paired with scanning speeds of up to 270 images per minute, a 69 percent improvement over prior models. Meanwhile, cloud-based capabilities include improved flexibility around where print jobs are stored and a Universal Output Queue that supports all devices to date with a single driver.
Finalist: Epson WorkForce Pro WF-C879R
Epson’s WorkForce Pro WF-C879R offers replaceable ink pack systems that enable users to print up to 86,000 ISO pages in black and up to 50,000 ISO pages in color. For print speeds, the WF-C879R provides speeds of up to 26 pages per minute in black and up to 25 ISO ppm in color.
Finalist: Lexmark MC3426adw
As part of Lexmark’s GO Line devices for SMBs, the MC3426adw is a multifunction device that offer strong speeds, but with a more compact form factor to fit into smaller spaces. The device’s time to first page can go as low as 5.9 seconds, while color printing can reach up to 24 pages per minute and mono can reach up to 40 pages per minute.
NETWORKING
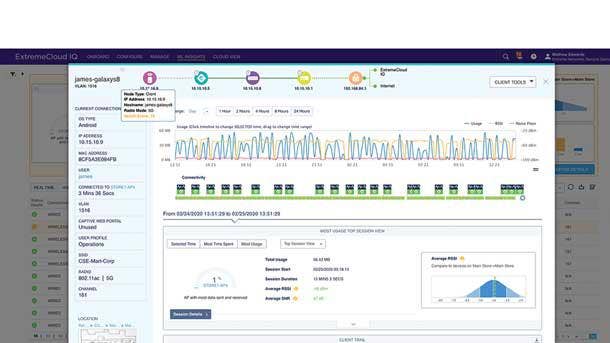
EXTREME NETWORKS EXTREMECLOUD IQ
WINNER: OVERALL
Enhanced insight, visibility and control—as well as new automation capabilities for IT administrators— come together in the ExtremeCloud IQ application from Extreme Networks. The enterprise network management app provides full visibility into every user and device in a network, as well as unified policy management across devices and sites. ExtremeCloud IQ also uses machine learning and AI to deliver actionable insight derived from the 3 PB of data that’s ingested by the company’s cloud instances each day. In addition, the new Co-Pilot feature provides automation capabilities that dramatically reduce the amount of context-gathering needed by IT administrators for handling support calls.
Subcategory Winner—Technology: Cisco Meraki MS390
With the Meraki MS390 next-generation access switch, Cisco launched its first Meraki switch that leverages the company’s Catalyst switching advancements—such as improved scalability and performance—paired with the simplified Meraki dashboard. The Cisco Meraki MS390 is also extendable for adopting new security policies and other new features.
Finalist: CommScope Ruckus Analytics
CommScope recently unveiled Ruckus Analytics, a cloud subscription-based service built on a foundation of AI that offers network intelligence while simplifying service assurance for MSPs managing their customers’ environments. The service uses AI derived from Ruckus networking elements, including access points and switches, to classify issues based on severity.
Finalist: HPE Aruba ESP
The HPE Aruba ESP (Edge Services Platform) provides a cloud-native approach for unifying, automating and protecting edge environments. Core components include AIOps, zero-trust network security and a unified infrastructure for campus, data center, branch and remote workers. The platform continuously analyzes data across domains, identifies anomalies and self-optimizes, while providing visibility and security for unknown devices on the network.
Finalist: Juniper Networks AP63
One of Juniper Networks’ latest Wi-Fi 6 access points is the AP63, a high-performance option for outdoor environments that can handle extreme weather conditions and temperatures. This access point also offers location-based services via a vBLE antenna, and can help educational institutions or medical facilities as they extend connectivity out into their parking lots or campuses.

PC-DESKTOP COMPUTERS
LENOVO THINKCENTRE M75N
WINNER: OVERALL
With many workers continuing to operate out of a home environment, workspace is at a premium. Lenovo is seeking to address the issue with its ThinkCentre M75n, a “nano”-sized PC the company says is the smallest desktop in its ThinkCentre lineup—with a volume of just 21 cubic inches and a weight of 1.1 pounds. The compact ThinkCentre M75n doesn’t compromise on performance and connectivity, however, with the desktop featuring AMD Ryzen Pro 3000 processors and a range of ports (including both USB-C and USB-A). Mounting the desktop behind a monitor or under a tabletop is also an option with compatible accessories, saving even more desk space.
Subcategory Winner—Technology, Customer Demand: Apple iMac 2020
For the refreshed version of its 27-inch iMac all-in-one, Apple added the latest 10th-generation Intel Core processors—including a 10-core processor option for the first time. The 27-inch iMac also can be configured with up to 128 GB of RAM (double the previous max) and comes with AMD Radeon Pro 5000 series graphics.
Finalist: Acer Aspire C 24 AIO
Acer’s Aspire C 24 is an all-in-one featuring a 23.8-inch FHD display, up to 2 TB of storage and up to 32 GB of RAM, in a slim, space-saving form factor. The display offers thin bezels with a screen-to-body ratio of 88 percent, while the desktop’s strong performance is powered by 11th-generation Intel Core processors and Nvidia GeForce MX 450 graphics.
Finalist: Dell OptiPlex 7780 AIO
With the OptiPlex 7780 AIO, Dell offers an all-in-one PC with a sizable 27-inch display and optional touch screen; up to a 10th-generation Intel Core i9 with 10 cores; Nvidia GTX 1650 graphics; and up to 64 GB of 2933 MHz DDR4 memory. The OptiPlex 7780 AIO is also equipped with AI-powered features such as ExpressResponse, which assesses user preferences and taps machine learning to more quickly launch frequently used applications.
Finalist: HP EliteOne 800 AIO G6
HP has touted its EliteOne 800 AIO G6 as “the world’s first commercial VR capable all-in-one,” thanks to its 10th-generation Intel Core processors and optional Nvidia GeForce RTX 2070 SUPER graphics. The EliteOne 800 AIO G6 comes with choices of two screen sizes, 23.8-inch or 27-inch, which offer low blue light and anti-glare technologies as well as micro-edge bezels on three sides.

PC-NOTEBOOKS
LENOVO THINKPAD X1 CARBON, 8TH GEN
WINNER: OVERALL
As Lenovo’s flagship ThinkPad, the latest X1 Carbon gets some notable upgrades that business users will appreciate. A new display option offers the Privacy Guard integrated privacy screen and high brightness, up to 500 nits, along with a touch screen. The eighth-generation X1 Carbon also offers an enhanced keyboard, with the inclusion of keys for unified communications, and features keys that are comfortable and deep for a notebook that only measures 0.58 of an inch thick. But the most stunning quality remains its portability, with the notebook weighing in at just 2.4 pounds. That makes the 14-inch X1 Carbon notably lighter even than other top-level notebooks that have smaller display sizes.
Subcategory Winner—Customer Demand: Apple MacBook Pro 2020
The 2020 update for the 13-inch MacBook Pro replaces the “butterfly” keyboard with Apple’s Magic Keyboard design, offering deeper key travel for improved typing comfort. The notebook also offers both eighth-generation and 10th-generation Intel Core processors to choose from, and adds a 32-GB RAM configuration for the first time on a 13-inch MacBook.
Finalist: Dell Latitude 9510 2-in-1
Dell’s Latitude 9510 stands out with a number of built-in AI capabilities. The notebook’s Intelligent Audio feature lets users configure their mic and speakers for the type of room they are in, while ExpressCharge learns how people use their PC and then adjusts policies to improve the battery life. Express Sign-In locks the notebook when users walk away and senses their proximity when they return—then automatically logs them in with Windows Hello facial recognition.
Finalist: Dynabook Portégé X30L
Dynabook’s Portégé X30L stands out with a weight of just 1.92 pounds--which makes it the world’s lightest 13.3-inch notebook with 10th-generation Intel Core processors. The laptop supports up to an Intel Core i7-10710U processor and offers up to 14 hours of battery life.
Finalist: HP Elite Dragonfly
HP’s Elite Dragonfly convertible features a fresh design paired with serious portability (with a starting weight of just 2.2 pounds) and battery life (up to 24.5 hours of battery life per charge). The design of the 13.3-inch notebook features a CNC-machined magnesium body and an iridescent “dragonfly blue” color.
Finalist: Microsoft Surface Book 3
Microsoft’s Surface Book 3 detachable laptop offers choices of display sizes (13.5 inches and 15 inches) and of quad-core, 10th-generation Intel Core processors (Core i5 or Core i7). The Surface Book 3 is also configurable with double the RAM of the previous model—32 GB—and offers “the fastest SSD we have ever shipped,” as well, Microsoft said.
POWER PROTECTION AND MANAGEMENT
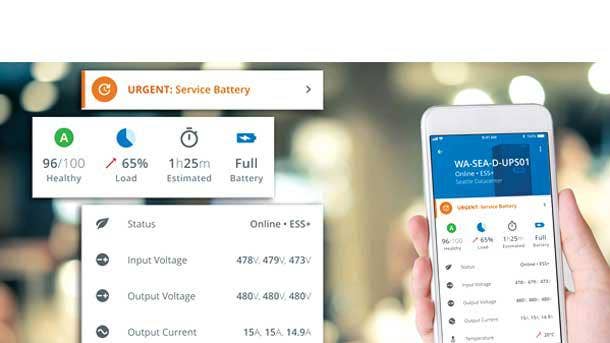
EATON PREDICTPULSE
WINNER: OVERALL
With the redesign of PredictPulse—Eaton’s remote management service for power infrastructure—a number of new features have been added to complement key existing capabilities of the service, such as providing analytics and recommendations for proactive management of infrastructure. Major upgrades for the redesigned PredictPulse service include an improved user experience on mobile devices and the web, a new notification system and enhanced communications about device and location performance. Leveraging customer input, the rebuilt PredictPulse service offers a new mobile portal interface to better enable data center and IT managers to monitor power infrastructure health and respond to incidents while off-site. The newly added PulseScore feature, meanwhile, provides communications about the health of a customer’s uninterruptible power supply system overall.
Subcategory Winner—Technology: APC by Schneider Electric Monitoring and Dispatch Services
With Monitoring and Dispatch Services, Schneider Electric serves as a third party to manage the operations of distributed IT infrastructure. Schneider Electric’s services include remote monitoring, troubleshooting and on-site remediation that is available as soon as the next business day.
Finalist: CyberPower CP1500PFCLCD
CyberPower’s CP1500PFCLCD—a mini-tower sinewave UPS system—features a number of updates from past models. Those include the addition of a color LCD panel to quickly confirm alerts and status; a tilting screen for improved viewing when the UPS is placed in a lower location; and a USB-C charging port for accommodating portable devices.
Finalist: Tripp Lite EdgeReady
EdgeReady represents Tripp Lite’s entry into the micro data center market, with modules that tie the rack enclosure, uninterruptible power supply, network management card, power distribution unit, sensors and management software into a single SKU.
Finalist: Vertiv Liebert PSI5
With the Liebert PSI5 Lithium-Ion UPS, Vertiv is offering a single-phase uninterruptible power supply with lithium-ion batteries for the first time. The use of lithium-ion enables extended runtime and reduced maintenance, and the system is available in a compact 2U rackmount/tower convertible configuration—all of which makes the Liebert PSI5 an ideal option for edge deployments.

PROCESSORS
INTEL XEON SCALABLE, 3RD GEN
WINNER: OVERALL
With Intel’s first batch of third- generation Xeon Scalable processors, the chipmaker is targeting enhanced performance—including for dataintensive AI workloads—in servers
with four and eight sockets. The new processors bring performance gains over Intel’s second-generation Xeon Scalable lineup and introduce an additional instruction set for built-in AI acceleration, which can boost training performance 1.93 times and inference performance 1.9 times when performing single-precision floating point math. The third-generation Xeon Scalable processors feature up to 28 cores, up to 3.1GHz in base frequency, up to 4.3GHz in single-core turbo frequency and up to six channels of DDR4-3200 memory with ECC support. They also support Intel’s new Optane Persistent Memory 200 Series, which can provide more than 225 times faster access to data than a mainstream NAND SSD.
Subcategory Winner—Customer Demand: AMD EPYC, 2nd Gen
AMD’s expanded second-generation, 7-nanometer EPYC lineup adds three processors that feature boost frequencies of up to 3.9GHz and L3 caches reaching 256 MB. Previously, the highest boost frequency achieved by an EPYC Rome processor was 3.4GHz. The three new processors—the 24-core EPYC 7F72, the 16-core EPYC 7F52 and eight-core EPYC 7F32—are being supported by server platforms from Dell EMC, Hewlett Packard Enterprise and Supermicro.
Finalist: AWS Graviton2 (Arm)
AWS Graviton2 processors use 64-bit Arm Neoverse cores with AWS-designed 7-nanometer silicon and provide up to 64 vCPUs, 25 Gbps of enhanced networking and 18 Gbps of EBS bandwidth. In June, AWS launched sixth-generation Amazon EC2 C6g and R6g instances—for compute-intensive workloads and processing large data sets in memory, respectively—which are powered by the Graviton2 processors.
Finalist: Nvidia A100 Tensor Core GPU
Nvidia’s recently launched A100 aims to revolutionize AI, with the ability to perform single-precision floating point math (FP32) for training workloads and eight-bit integer math (INT8) for inference 20 times faster than the V100 GPU that came out in 2017. The A100 also uses Nvidia’s third-generation Tensor Cores that come with a new TF32 For AI format, which enables single-precision floating point acceleration by compressing the number of bits needed to complete math equations.

PUBLIC CLOUD
MICROSOFT AZURE
WINNER: OVERALL
Microsoft’s Azure public cloud is thriving because the company truly understands how businesses want to use it, said Kelly Yeh, president of Phalanx Technology Group. “That’s what I always say is the best thing about Microsoft,” Yeh said. “We do both Azure and AWS. With AWS, we only use it for our customers that are e-commerce sites or websites. The Microsoft Azure environment is far superior if you’re trying to move your on- prem server farm. So unless you’re heavily invested in Linux servers on-prem, of course you’re going to spin it up in Microsoft’s Azure. It’s just so much easier to manage than AWS.” Solution providers ranked Azure No. 1 in Technology and Customer Demand and No. 2 in Revenue and Profit.
Subcategory Winner—Revenue and Profit: Oracle Cloud
In CRN’s 2020 Products of the Year survey, solution providers gave Oracle Cloud the No. 4 overall ranking among public cloud providers. However, Oracle Cloud did rank at No. 1 in the Revenue and Profit subcategory. The platform also ranked at No. 4 in Technology and at No. 4 in Customer Demand in the survey.
Finalist: Amazon Web Services
In CRN’s 2020 Products of the Year survey of solution providers, Amazon Web Services ranked at No. 2 overall among the five public cloud providers included in the survey—a tie with Google Cloud. AWS ranked at No. 2 in the Technology subcategory while ranking at No. 3 in Customer Demand and at No. 4 in Revenue and Profit.
Finalist: Google Cloud
As mentioned, Google Cloud tied with AWS in getting the No. 2 overall ranking from solution providers for Public Cloud in CRN’s 2020 Products of the Year survey. Google Cloud ranked at No. 2 in the Customer Demand subcategory, at No. 3 in Revenue and Profit, and at No. 3 in Technology.
Finalist: IBM Cloud
IBM Cloud was ranked by solution providers at No. 5 overall in Public Cloud in CRN’s 2020 Products of the Year survey. IBM Cloud ranked at No. 5 in all three subcategories in the survey for Public Cloud.
SD-WAN
VMWARE SD-WAN BY VELOCLOUD
WINNER: OVERALL
As SD-WAN increasingly serves as a key part of the broader area known as Secure Access Service Edge (SASE), VMware SDWAN by VeloCloud has been advancing its offering to deliver a powerful SASE platform for businesses. The platform brings together VMware’s hyperscale SD-WAN architecture, which is based on thousands of VMware SD-WAN Cloud Gateways, with a wide network of cloud services. The combination delivers an ideal user experience through identifying each client and optimizing application traffic across the cloud. VMware SD-WAN by VeloCloud also provides robust, integrated security with its SASE platform, including key capabilities such as zero-trust network access, cloud access security broker and secure web gateway. Ultimately, VMware SD-WAN by VeloCloud provides all users and devices with a secure and consistent experience, even across a distributed workforce.
Subcategory Winner—Revenue and Profit: Palo Alto Networks CloudGenix SD-WAN
In April, Palo Alto Networks completed its acquisition of SD-WAN heavy-hitter CloudGenix to bolster its Secure Access Service Edge platform. CloudGenix is enhancing Palo Alto Networks’ capabilities around intelligently performed on-boarding of remote branches and retail stores into its SASE platform, Prisma Access.
Finalist: Aryaka SmartServices
With the SmartServices global managed SD-WAN platform, Aryaka offers features such as SmartManage for global orchestration and visibility; SmartConnect for connectivity that includes dedicated backbone, broadband internet and MPLS; SmartSecure for edge and cloud-based security; SmartOptimize for multisegment network and application optimization; and SmartCloud for direct connectivity to the major cloud platforms.
Finalist: Cisco SD-WAN
Cisco’s recently launched Secure Access Service Edge offering features integration between the company’s flagship SD-WAN offering, powered by Viptela, and its cloud-based secure web gateway, Cisco Umbrella. The fully integrated SASE offering includes an SD-WAN dashboard that can be used to rapidly deploy Cisco Umbrella security across all sites and users.
Finalist: Silver Peak Unity EdgeConnect
Silver Peak, acquired by Hewlett Packard Enterprise in late September, recently refreshed its Unity EdgeConnect SD-WAN edge platform—which now has been injected with Unity Orchestrator Global Enterprise management software, a SaaS-based application designed for large-scale global enterprises with multiple divisions, business units or subsidiaries that each require a dedicated SD-WAN fabric.
Finalist: Versa Networks Secure SD-WAN
Versa Networks recently expanded its Secure SD-WAN offerings with the addition of the Versa Secure Access offering, which provides highly scalable remote access for customers to securely connect to applications in both public and private clouds. The offering combines security functions with SD-WAN including a stateful firewall, DOS protection, a next-generation firewall, an intrusion prevention system and URL filtering on end users’ devices.
SECURITY-CLOUD
CISCO SECUREX
WINNER: OVERALL
With the cloud-native SecureX platform, Cisco is dramatically enhancing security visibility with powerful analytics and automation—ultimately accelerating threat detection and response. SecureX is capable of analyzing traffic from the public cloud, as well as from networking infrastructure and private data centers, to rapidly identify the targets of cyberattacks and enable remediation. SecureX provides broad visibility of security environments at a customer, while deploying analytics to improve the detection of policy violations and unknown threats. The offering also helps to make operations more efficient through the automation of typical security workflows, such as threat investigation and remediation.
Subcategory Winner—Technology: Palo Alto Networks Prisma
Palo Alto Networks’ Prisma offering is a cloud-native security suite that covers multi-cloud and hybrid cloud environments with capabilities in data security, web application and API security, identity-based microsegmentation and identity and access management security. Prisma stands out by offering both cloud workload protection and cloud security posture management and one platform using a Software-as-a-Service model.
Finalist: Check Point CloudGuard Cloud Native Security
With its CloudGuard Cloud Native Security offering, Check Point Software Technologies offers advanced threat prevention for protecting against attacks such as advanced persistent threat and zero-day. The offering also provides unified visibility across a customer’s multi-cloud environments—as well as automation capabilities such as auto-provisioning and auto-scaling for securing workloads in any cloud.
Finalist: McAfee MVision Cloud
McAfee MVision Cloud combines data protection with threat prevention across Software-as-a-Service, Infrastructure-as-a-Service and Platform-as-a-Service environments. The platform enables organizations to adopt cloud services with all of the required security, governance and compliance capabilities. Users can now rapidly detect zero-day threats that are based on behavior, thanks to McAfee’s Gateway Anti-Malware engine.
Finalist: WatchGuard Cloud Platform
Focused on enabling managed security services, the WatchGuard Cloud Platform provides a single location for managing, configuring and reporting on security services for each customer. The cloud-delivered platform also includes capabilities such as proactive alerts and notifications and role-based access control that is built in.
SECURITY-EMAIL
BARRACUDA ESSENTIALS
WINNER: OVERALL
As a comprehensive offering for Microsoft Office 365 email protection, Barracuda Essentials provides everything from security, to backup and archiving, to cloud-based management. In security, Barracuda Essentials offers advanced threat protection, which scans attachments and blocks those that are suspicious; anti-phishing capabilities; malware protection; AI-driven defense against spear phishing and cyberfraud; and numerous other email protection features. Barracuda Essentials also goes beyond security by addressing the need for email archiving capabilities (which enable granular retention policies); compliance and e-discovery features; backup, recovery and business continuity capabilities; and email management via a centralized cloud platform for managing configuration and policies.
Finalist: Cisco Cloud Mailbox Defense
Cisco’s Cloud Mailbox Defense offers a simplified method for deploying security for Office 365, ideal for organizations with smaller security and IT staffs. The offering leverages the Cisco Talos threat intelligence team to add an additional layer of security around blocking URLs and threat files.
Finalist: Mimecast Email Security
With the launch of Mimecast’s Email Security 3.0, the company has rolled out key updates such as security awareness training integration. Mimecast Awareness Training is now fully integrated into the cloud-based Email Security platform, making it easier for awareness training to be deployed as part of an organization’s broader security ecosystem.
Finalist: Proofpoint BEC/EAC Integrated Solution
Earlier this year, Proofpoint debuted what it called the first offering to address both business email compromise (BEC) and email account compromise (EAC) attacks. The offering combines Proofpoint’s secure email gateway with capabilities such as advanced threat protection, email authentication, threat response, cloud account protection and security awareness training.
Finalist: Zix Secure Modern Workplace
Leveraging its acquisition of AppRiver, Zix recently launched its Secure Modern Workplace offering, powered by the company’s Secure Cloud offering. Advanced threat protection capabilities in Secure Cloud range from sandboxing and messaging protection to integration with SIEM (Security Information and Event Management) platforms. Previously, Zix’s technology had been mostly focused on protecting against phishing, malware and business email compromise attacks.
SECURITY - ENDPOINT PROTECTION
CROWDSTRIKE ENDPOINT RECOVERY SERVICES
WINNER: OVERALL
For its Endpoint Recovery Services offering, CrowdStrike brings together its Falcon endpoint protection platform with threat intelligence and response to facilitate a rapid recovery after an intrusion. Incident recovery is enabled with the help of capabilities such as comprehensive endpoint visibility, via CrowdStrike’s Threat Graph, and analysis from experienced security professionals. The services do not require on-site visits and installations to deploy the Falcon platform, and also spare organizations from needing to reimage or reissue devices. CrowdStrike’s Endpoint Recovery Services provide immediate disruption of attacks and full remediation—accelerating the restoring of operations and avoiding extensive downtime.
Finalist: Kaspersky Endpoint Security Cloud
With the latest version of Kaspersky’s Endpoint Security Cloud, the offering has added features such as cloud discovery, which enables IT administrators to address shadow IT by ensuring compliance with corporate security policies. The feature provides control over the use of applications and sites that are commonly used by workers, but are also potentially insecure.
Finalist: McAfee MVision EDR
For its MVision EDR offering, McAfee recently launched new features including Automated AI-Guided Investigations—which offer improved guidance of customer investigations using internally generated machine learning and threat intelligence—and Advanced Analytics, which identify and prioritize suspicious behavior from contextually rich endpoint data.
Finalist: Sophos Intercept X
Sophos recently debuted a major upgrade to its Intercept X offering—including an update of the company’s Endpoint Detection and Response solution within several new versions of Intercept X. The updated EDR offering includes new capabilities such as Live Discover (for pinpointing activity and answering threat hunting questions) and Live Response (which enables remote response to endpoints via a command line interface).
Finalist: VMware Carbon Black
Aimed at providing consolidated and cloud-native endpoint protection, VMware’s Carbon Black Cloud offering combines multiple powerful endpoint security features—such as continuous collection and analysis of endpoint activity data—into one lightweight agent that is complemented by a console that is easy to operate.
Finalist: Webroot Business Endpoint Protection
Now owned by OpenText, Webroot offers differentiators for its Business Endpoint Protection offering such as the Webroot Evasion Shield. The feature brings protection against threats such as file-based and fileless script attacks; malicious JavaScript, VBScript, PowerShell and macros; and detection of scripts that are running in an environment. Other key capabilities include contextual threat intelligence and a cloud-based management console.

SECURITY-NETWORK
FORTINET FORTIGATE 1800F
WINNER: OVERALL
Fortinet is accelerating data center security performance with its seventh-generation network processor—the NP7—which made its first appearance in the company’s FortiGate 1800 firewall earlier this year. The custom-designed NP7 is able to speed up the Fortinet 1800F to the point where it’s able to sit at the core of the network and support VXLAN network virtualization technology. The processor can thus serve as the building block for hyperscale applications, delivering performance and fast connections across the board. In fact, the FortiGate 1800 firewall with NP7 technology is 14 times faster than the industry average for products at a similar price point, according to Fortinet. The NP7 debuted with the launch of the midrange FortiGate 1800 in February and is now powering several additional FortiGate firewalls as well.
Finalist: Check Point Fast Track Network Security
Check Point’s Fast Track Network Security suite offers protection against advanced threats using higher-performance security gateways and Check Point’s updated R80 unified security software. The Fast Track Network Security gateways offer more than double the performance of competing appliances, according to Check Point, and bring capabilities such as the company’s ThreatCloud threat intelligence and SandBlast zero-day protection.
Finalist: Palo Alto Networks CN-Series
The Palo Alto Networks CN-Series is a containerized version of the company’s firewall that protects inbound, outbound and east-west traffic between container trust zones along with other components of enterprise IT environments. The CN-Series can be used to protect critical applications against known vulnerabilities as well as both known and unknown malware until patches can be applied to secure the underlying resource.
Finalist: SonicWall TZ Firewall Series
Along with breaking new ground in the industry as the first firewalls in a desktop form factor with multi-Gigabit interfaces, SonicWall’s TZ570 and TZ670 Series next-generation firewalls bring support for TLS 1.3 decryption and 5G; integrated support for SD-WAN; up to 10 ports and 256 GB of storage; optional PoE and Wi-Fi; and the ability to connect up to 1.5 million devices.
Finalist: Sophos XG Firewall 18
With Sophos XG Firewall 18, the company provides enhanced visibility by inspecting all encrypted traffic, making it more difficult for adversaries to hide information in varying protocols. The offering also retains high levels of performance, thanks to improvements in the way that Sophos determines whether apps and traffic need to go through its deep packet inspection engine.

SMARTPHONES
APPLE IPHONE 11 PRO MAX
WINNER: OVERALL
As the top-tier model in Apple’s iPhone 11 lineup, the iPhone 11 Pro Max featured the largest display in the lineup at 6.5 inches along with vibrant OLED display technology. A major update on the smartphone’s rear camera setup brought the device to a
triple-camera system, including an ultrawide camera for the first time. On battery life, the iPhone 11 Pro Max received a boost of up to five hours longer usage than its predecessor, the iPhone XS Max. And on performance, the six-core A13 Bionic chip in the iPhone 11 Pro Max has enabled speeds that are only outpaced in the smartphone world by its successor iPhone 12 models that launched in October.
Subcategory Winner—Revenue and Profit: Samsung Galaxy Note 20 Ultra
Samsung’s Galaxy Note 20 Ultra features an improved S Pen stylus, with noticeably reduced latency and new capabilities such as the ability to annotate PDFs. The Note 20 Ultra also offers a 120hz refresh rate for smoother display motion on its 6.9-inch OLED screen; 5G connectivity; 12 GB of RAM; and a three-camera system on the rear offering up to 50X zoom.
Finalist: Google Pixel 4
Google’s Pixel 4 features a 5.7-inch OLED display and new features such as “Motion Sense,” which brings hand gesture control to key apps in the phone. The Pixel 4 also adds a second rear camera to its setup, with a 16-megapixel telephoto camera joining the 12.2-megapixel main rear camera.
Finalist: Motorola Edge Plus
As a premium offering in Motorola’s smartphone line, the Motorola Edge Plus includes a 6.7-inch OLED display with a 90hz refresh rate for smoother display motion; 5G connectivity; and strong performance from the inclusion of Qualcomm’s Snapdragon 865 Mobile Platform. The phone’s performance is also bolstered by an impressive 12 GB of RAM.
Finalist: OnePlus 8 Pro
Key features on the OnePlus 8 Pro include a 120Hz refresh rate for a smooth display experience and up to 1,300 nits of brightness on the phone’s 6.78-inch AMOLED screen. The OnePlus 8 Pro also supports 5G connectivity and includes 12 GB of RAM for improved performance, along with offering the company’s first quad-camera system.

STORAGE - ENTERPRISE EXTERNAL STORAGE HARDWARE
HPE PRIMERA 600
WINNER: OVERALL
With the latest update to its Primera 600 storage system, Hewlett Packard Enterprise is enabling new levels of performance and agility for partners and customers—who can now spend less time managing and tuning mission-critical storage infrastructure. In the past, storage administrators would have had to act on the AI-driven recommendations of the system, but that’s changed with the recent Primera 600 enhancements. Now, thanks to a major upgrade to the InfoSight AI capabilities, the system can take dynamic action to automatically resolve storage management issues. HPE Primera thus goes beyond predictive analytics to take direct actions that optimize resource utilization, dramatically improving storage performance for customers. Ultimately, Primera’s ability to automatically implement solutions to storage issues is providing a critical differentiator for HPE partners to become more strategic with their customers.
Subcategory Winner—Technology, Customer Demand: Dell EMC PowerStore 9000
Featuring built-in machine learning and automation, Dell EMC PowerStore is a programmable infrastructure that dramatically improves everything from application development to deployment. The top-of-the-line PowerStore 9000 offers Intel Xeon Scalable processors with 112 cores per array and a clock speed of 2.1GHz, as well as 2.56 TB of memory per appliance.
Finalist: IBM FlashSystem 9200
IBM’s FlashSystem 9200 offers three to four times the performance and 17 times the rack density of the company’s FlashSystem A9000 line—but at a price that is 40 percent to 60 percent less expensive, depending on configuration.
Finalist: NetApp AFF A800
NetApp’s AFF A800 is an NVMe enterprise all-flash array aimed at offering speedy performance and low latency for applications, including AI and machine learning applications. The array can deliver up to 11.4 million IOPS at 1 millisecond latency, while enabling the management of NAS containers of up to 20 PB.
Finalist: Pure Storage FlashArray//X90
Earlier this year, Pure Storage unveiled its third-generation FlashArray//X portfolio of all-NVMe arrays, including the top-tier FlashArray//X90. Key updates include an increase in performance of up to 25 percent, compared with the prior generation, with updated controllers that include Intel’s latest Xeon Scalable processors.

STORAGE - SMB EXTERNAL STORAGE HARDWARE
DELL EMC POWERSTORE 1000T
WINNER: OVERALL
Though it’s the base model in Dell EMC’s PowerStore offering, the PowerStore 1000T includes the same scale-up, scale-out architecture of the higher-tier models. The all-fl ash PowerStore offering leverages machine learning and automation technologies to provide a programmable infrastructure, improving everything from application development to deployment. The system’s machine-learning engine delivers optimized performance and reduced cost through automation of processes such as initial volume placement and load balancing. The PowerStore 1000T differs from higher-tier models in offering Intel Xeon Scalable processors with fewer cores per array (32) and a lower clock speed (1.8GHz), as well as less memory per appliance (384 GB). Other key components of the Dell EMC PowerStore offering include support for orchestration frameworks such as Kubernetes and Ansible, as well as VMware integration.
Finalist: IBM FlashSystem 5000
Key features of the IBM FlashSystem 5000 include Easy Tier, which uses AI to detect storage usage patterns by workloads and automatically moves data among tiers of storage—ultimately optimizing the use of different media with differing price and performance characteristics.
Finalist: HPE Nimble Storage HF20
With its Nimble Storage HF20 adaptive flash array, Hewlett Packard Enterprise is driving performance gains of up to 65 percent compared with the previous generation. That enhanced performance is paired with HPE Nimble Storage’s signature predictive analytics, which can predict and resolve 86 percent of problems before the issues are discovered.
Finalist: Lenovo ThinkSystem DE6000F
Lenovo’s ThinkSystem DE6000F is an all-flash array that pairs strong performance with an “attractive” cost, Lenovo said. The array provides up to 1 million IOPS with latency of less than 100 microseconds, while offering simplified integration through a suite of application plugins and APIs.
Finalist: NetApp AFF C190
NetApp’s entry-level all-flash offering, the AFF C190, provides benefits such as rapid provisioning of storage and management of file and block data on one system—all at an affordable price point, according to the company. Workloads can be deployed in less than 10 minutes with the AFF C190, NetApp said, thanks to a simplified wizard that guides users through configuration and built-in workflows for key applications.