The 10 Coolest Big Data Tools Of 2021 (So Far)
Managing ever-growing volumes of data continues to be a challenge for business and organizations. Here are 10 cool big data management tools and platforms that have caught our attention.

Big Challenges In Big Data Management
The global COVID-19 pandemic hasn’t slowed the exponential growth of data: IDC recently calculated that 64.2 zettabytes of data was created, consumed and stored globally in 2020. And the market researcher forecasts that global data creation and replication will experience a 23 percent CAGR between 2020 and 2025.
The good news is that innovative IT vendors, both established companies and startups, continue to develop next-generation platforms and tools for a range of data management tasks including data operations, data integration, data preparation, data science, data governance, data discovery and data lineage tracking.
Here’s a look at some cool big data management tools that have caught our attention at the midpoint of 2021.
For more of the biggest startups, products and news stories of 2021 so far, click here .

Airbyte
Early stage startup Airbyte (founded in January 2020) develops an open-source data integration platform for replicating and consolidating data from different sources into databases, data warehouses and data lakes. Organizations can use the platform to build pipelines between data sources, including operational applications such as Salesforce and Facebook Ads, and cloud data warehouses such as Snowflake and AWS Redshift.
While Airbyte is competing with a host of established vendors of ETL (extract, transform and load) tools, the company touts the simplicity of its software, maintaining that even nontechnical business analysts can use it to replicate data. And the startup’s open-source approach has created an active user community that is rapidly developing additional connectors for the platform.
Between January and May of this year, Airbyte’s customer base grew eight-fold to more than 2,000. The San Francisco-based company raised $26 million in Series A funding in May.

Alation Cloud Service
Alation has expanded its original data catalog software into a platform for a range of enterprise data intelligence tasks including data search and discovery, data governance, data stewardship, analytics and digital transformation.
In April the company extended those capabilities to the cloud with its new Alation Cloud Service, a comprehensive cloud-based data intelligence platform that can connect to any data source—in the cloud or on-premises—through cloud-native connectors.
The company, based in Redwood City, Calif., said the new cloud offering, with its continuous integration and deployment options, provides a simple way to drive data intelligence across an organization’s hybrid architecture with lower maintenance and administrative overhead and faster time-to-value.

AtScale CloudStart
AtScale’s flagship product, the Intelligent Data Virtualization platform, uses semantic layer technology to provide cloud-based OLAP (online analytical processing) analytics for distributed data—no matter where it resides.
The Boston-based company’s new AtScale CloudStart, launched in May, provides a way to build analytics infrastructure on cloud data platforms by integrating AtScale’s semantic layer with cloud data management systems including Snowflake, Microsoft Azure Synapse SQL, Google BigQuery, Amazon Redshift and DataBricks.
CloudStart makes it easier to connect business analytics tools like Tableau, Power BI and Looker to multiple cloud data sources.

CockroachDB 21.1
New York-based Cockroach Labs develops CockroachDB, a cloud-native, distributed SQL database that’s designed to handle workloads with huge volumes of transactional data.
Cockroach launched CockroachDB 21.1 in May, making it simpler to tie data to specific locations anywhere in the world using a single database—a significant challenge as more countries and regions are demanding that data remain within their borders.
The new database release provides a unique architecture and built-in ability to manage the geo-location of data anywhere in the world using a few SQL statements—no schema changes or manual sharding—providing users with near-instantaneous access to data while ensuring local regulatory compliance.
The release minimizes transactional latency by placing data physically close to end users, eliminates outages by using redundancies that survive regional or cloud failures, and supports local data privacy requirements.

Databricks Delta Sharing
Databricks launched the Delta Sharing initiative in May to create an open-source data sharing protocol for securely sharing data across organizations in real time, independent of the platform on which the data resides.
Delta Sharing, included within the open-source Delta Lake 1.0 project, establishes a common standard for sharing all data types—structured and unstructured—with an open protocol that can be used in SQL, visual analytics tools, and programming languages such as Python and R. Large-scale datasets also can be shared in the Apache Parquet and Delta Lake formats in real time without copying.
The Delta Sharing initiative has already attracted support from a number of data providers, including the Nasdaq, S&P and Factset, and leading IT vendors including Amazon Web Services, Microsoft and Google Cloud, according to Databricks.
Delta Sharing is the latest open-source initiative from Databricks, one of the most closely watched big data startups. Founded by the developers of the Apache Spark analytics engine, San Francisco-based Databricks markets the Databricks Lakehouse Platform, its flagship unified data analytics platform.

Dremio Dart Initiative
In June data lake engine developer Dremio launched its Dremio Dart Initiative, which the Santa Clara, Calif.-based company boldly declared to be “a major step forward in obsoleting the cloud data warehouse.”
Dremio’s software provides a way to directly analyze data in data lakes—huge stores of unorganized data—without having to copy and move data into data warehouse systems. The Dart Initiative takes that to the next level by making it possible to run all mission-critical SQL workloads directly on a data lake.
The initial Dart Initiative capabilities, built into the most recent Dremio release, include faster query execution and optimal query planning, enhanced automated management of query acceleration, support for a broader range of SQL workloads, and improved distributed and real-time metadata management to support larger datasets.

Nexla Nexsets
Nexla has developed a unified data operations platform—which the company calls a “converged data fabric”—for creating scalable, repeatable and predictable data flows throughout an organization. The software is used to integrate, automate and monitor incoming and outgoing data for data use cases including data science and business analytics.
Nexsets, Nexla’s most recent addition to its technology portfolio, automates manual, time-consuming data engineering tasks, making it easier to access, integrate and transform data that may be scattered across disparate systems. Nexsets creates logical views of data without the need for data copying or duplication, providing business users with access to a curated data view they can use to create reports and dashboards, move data to an application or store the data in the cloud.
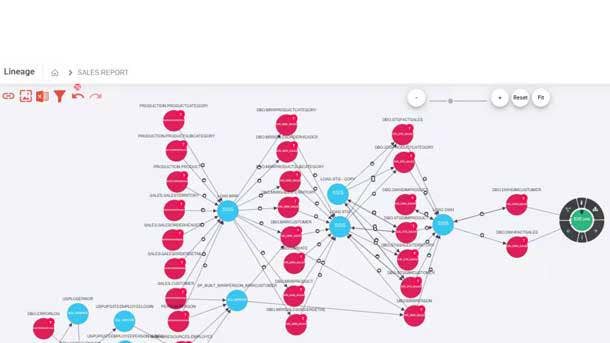
Octopai Data Lineage XD
Octopai, based in Tel Aviv, Israel, develops software tools that automate metadata management and analysis, helping organizations locate and understand their data for improved operations, data quality and data governance.
On May 10 Octopai debuted Data Lineage XD, an advanced, multidimensional data lineage platform the company said takes data lineage to the next level. Data Lineage XD uses visual representations to display data flow from its source to its destination, providing users with a more complete understanding of data origin, what happened to it and where it is distributed within a data landscape.
Such capabilities are used to track data errors, implement process changes, manage system migrations and improve business analytics efficiency.
Splunk Observability Cloud and Splunk Security Cloud
Splunk has been expanding its product portfolio to leverage the capabilities of its “data-to-everything” Splunk Enterprise and Splunk Cloud platforms for capturing, indexing and correlating machine data in a searchable repository.
IT system and application monitoring is one of the most common uses for the Splunk platforms. Splunk, based in San Francisco, has doubled down on that by developing the Splunk Observability Cloud for IT and DevOps Teams, a package of Splunk software including Splunk Log Observer, Splunk Real User Monitoring, Splunk Infrastructure Monitoring, Splunk APM and Splunk On-Call.
Observability Cloud for IT and DevOps Teams debuted in beta in October 2020 and became generally available in May.
Systems monitoring and data collection for cybersecurity tasks is another major application of the Splunk platform. In June Splunk launched the Splunk Security Cloud, a data-centric security operations platform that leverages its “data-to-everything” technology to provide advanced security analytics, automated security operations and integrated threat intelligence capabilities.

YugabyteDB
Yugabyte, based in Sunnyvale, Calif., is one of a new generation of database developers offering technology designed to outperform and out-scale legacy database systems. YugabyteDB is a high-performance, distributed SQL database for building global, internet-scale applications.
In May Yugabyte released YugabyteDB 2.7 with a comprehensive set of deployment options for organizations looking to scale distributed SQL across hybrid cloud environments using Kubernetes platforms such as Red Hat OpenShift and VMware Tanzu.
The company said YugabyteDB’s support for public and cloud-native environments enables businesses and organizations to follow through on their strategic Kubernetes, distributed SQL and microservices initiatives while avoiding cloud lock-in.
The YugabyteDB 2.7 edition can roll back unintended changes and restore the database to an earlier point in time. It also supports Tablespaces for fine-grained control of data distribution across regions and availability zones.