Adam Selipsky re:Invent Keynote: 8 Big New AWS Products
From the new AWS Supply Chain and Amazon DataZone solutions to AWS SimSpace Weaver and EC2 Hpc6id Instances, CEO Adam Selipsky talks about eight big launches during his keynote at AWS re:Invent 2022.

Amazon Web Services CEO Adam Selipsky took to the main stage at AWS re:Invent 2022 on Tuesday to unleash a slew of new AWS services and solutions for the hundreds of thousands of attendees around the world.
“I’m happy to welcome over 50,000 customers and partners here in Las Vegas and over 300,000 attendees virtually around the world,” said Selipsky to open up his keynote speech at AWS re:Invent 2022. “We’ve got so much innovation to share.”
Selipsky spoke in front of thousands in attendance at The Venetian conference center in Las Vegas launching 10 new products—from the new AWS Supply Chain and Amazon DataZone to AWS SimSpace Weaver and new EC2 Hpc6id Instances.
[Related: Adam Selipsky: Why Partners Should Pick AWS Vs. Cloud Rivals]
AWS re:Invent 2022
CEO Adam Selipsky’s keynote helped kick off AWS’ largest annual event of the year: re:Invent 2022.
Attendees get to see AWS cloud technology first-hand, can receive various trainings, visit hundreds of vendor showcase areas, network with thousands of other IT professionals and get key insights from AWS leaders.
“I hope you’ll take advantage of the incredible learning that’s here this week from attending your choice of over 2,300 different sessions to connect with partners at the Expo Center or meeting other members of the AWS community,” Selipsky told attendees during his re:Invent keynote. “There really is no other show like this.”
This is Adam Selipsky’s second time hosting AWS re:Invent as CEO of AWS, replacing Andy Jassy who is now CEO of parent company Amazon.
During his first turn at AWS from 2005 to 2016, Selipsky took the company from pre-revenue to a $13 billion business while also launching the AWS Partner Network in 2012. After five years as CEO of data analytics software vendor Tableau, he officially took over the AWS CEO reins in July 2021.
CRN breaks down eight of Selipsky’s bullish statements during his keynote regarding new AWS products launched at re:Invent 2022 today.
* Amazon OpenSearch Serverless
* Aurora Zero-ETL With Amazon Redshift
* Amazon DataZone
* Amazon Security Lake
* Amazon EC2 Hpc6id Instances
* AWS SimSpace Weaver
* AWS Supply Chain
* Amazon Redshift Integration For Apache Spark
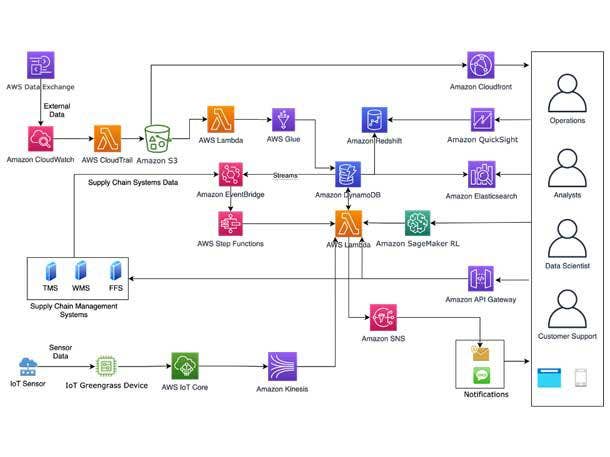
AWS Supply Chain: AWS ‘To Solve Your Hardest Supply Chain Problems’
AWS Supply Chain is a new cloud-based application that helps supply chain leaders mitigate risks and lower costs to increase supply chain resilience.
“AWS Supply Chain helps you mitigate risk and lower costs by giving you a unified view of your supply chain, and surfaces the best actionable insights all with pay-as-you-go pricing and no upfront licenses,” said Selipsky.
AWS Supply Chain unifies supply chain data, provides ML–powered actionable insights, and offers built-in contextual collaboration—all of which helps users increase customer service levels by reducing stock outs while helping lower costs from overstock, AWS CEO said.
AWS Supply Chain provides a real-time visual map feature showing the level and health of inventory in each location and targeted watchlists to alert you to potential risks. When a risk is uncovered, AWS Supply Chain provides inventory rebalancing recommendations and built-in, contextual collaboration tools that make it easier to coordinate across teams to implement solutions.
AWS Supply Chain connects to a customers’ existing ERP and supply chain management systems, without replatforming, upfront licensing fees, or long-term contracts.
“This is just the beginning. We’re going to continue to invest here and work to solve your hardest supply chain problems,” said Selipsky.

Amazon OpenSearch Serverless: The ‘Time Is Now’
Amazon OpenSearch Service is now offering a new serverless option: Amazon OpenSearch Serverless.
“Many of you have been asking us, ‘When can we get a serverless option for OpenSearch? Well, that time is now,” said Selipsky. “You can use this OpenSearch Serverless platform to perform interactive analytics, real time application monitoring, website search, and more without having to worry about provisioning, configuring and scaling infrastructure.”
“Now we have serverless options for all of our analytics services, and no one else can say that,” said AWS CEO.
Selipsky said the new solution simplifies the process of running petabyte-scale search and analytics workloads without having to configure, manage, or scale OpenSearch clusters. OpenSearch Serverless automatically provisions and scales the underlying resources to deliver fast data ingestion and query responses for the most demanding and unpredictable workloads.
With OpenSearch Serverless, customers pay only for the resources consumed.
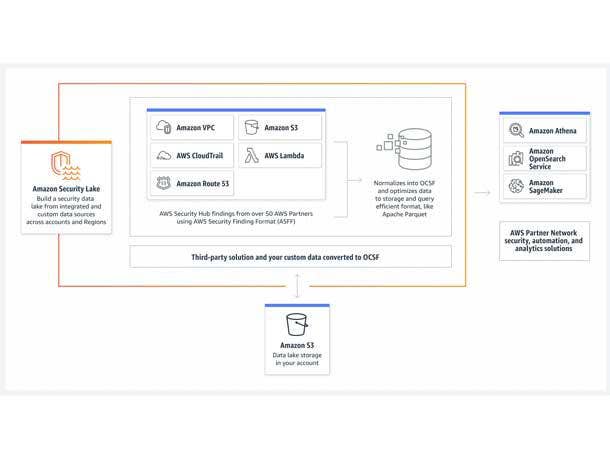
Amazon Security Lake: ‘Automatically Build Security Data Lakes With Just A Few Clicks’
AWS launched the new Amazon Security Lake that automatically centralizes security data from cloud, on-premises, and custom sources into a purpose-built data lake stored in an customers’ account.
“Security Lake is a data lake that makes it easy for security teams to automatically collect, to combine, and to analyze security data at petabyte scale,” said Selipsky. “Security Lake is optimized for security data. You can now automatically build security data lakes with just a few clicks.”
AWS CEO said Security Lake makes it easier to analyze security data so that you can get a more complete understanding of your security across the entire organization. It improves the protection of workloads, applications, and data, while automatically gathering and managing all security data across accounts and regions.
“Security Lake automatically collects and aggregates security data for partner solutions like Cisco, CrowdStrike and Palo Alto Networks, as well as more than 50 security tools integrated into Security Lake,” he said.
Security Lake manages the lifecycle of your data with customizable retention settings and storage costs with automated storage tiering.
“We look forward to seeing how you’re going to use Amazon Security Lake to improve your security posture for reducing the time to resolve security issues, and to simplify the lives of your security and your operations teams,” he said.

‘Best Of Both Worlds’: AWS Aurora Zero-ETL With Amazon Redshift
For the first time ever, Amazon Aurora will now support zero-ETL (extract, transform and load) integration with Amazon Redshift, to enable near real-time analytics and machine learning using Amazon Redshift on petabytes of transactional data from Aurora.
This integration brings together transactional data with analytics capabilities, eliminating all the work of building and managing custom data pipelines between Aurora and Redshift—it’s incredibly easy,” said Selipsky.
“After [the data] comes into Aurora, seconds later, the data is seamlessly made available inside of Redshift,” said Selipsky. “And you can replicate data from multiple Aurora databases in the same Redshift instance.”
AWS CEO said users don’t have to build and maintain complex data pipelines to perform extract, transform, and load (ETL) operations.
“The entire system is serverless and dynamically scales up and down based on the data volume. So there’s no infrastructure to manage. Now, you really have the best of both worlds—fast, scalable transactions in Aurora, together with scalable analytics in Redshift, all in one seamless system.”
The zero-ETL integration also enables customers to analyze data from multiple Aurora database clusters in the same new or existing Amazon Redshift instance to derive holistic insights across many applications or partitions.

Amazon DataZone: ‘There’s Really Nothing Else Like It’
AWS launched a new data management service that makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on-premises, and third-party sources with Amazon DataZone.
“DataZone enables you to set your data free throughout the organization safely by making it easy for admins and data stewards to manage govern access to data,” said Selipsky. “It makes it easy for data engineers, data scientists, product managers, analysts and other business users to discover, use and collaborate around that data to drive insights for your businesses.”
Data producers use Amazon DataZone’s web portal to set up their own business data catalog by defining their data taxonomy, configuring governance policies, and connecting to a range of AWS services such as Amazon S3 and Amazon Redshift, partner solutions like Salesforce and ServiceNow, and on-premises systems.
Selipsky said Amazon DataZone removes the heavy lifting of maintaining a catalog by using machine learning to collect and suggest metadata for each dataset and by training on a customer’s taxonomy and preferences to improve over time.
“Now you have an easy way to organize, discover, and collaborate on data across the company. There’s really nothing else like it, and I’m really excited to see how you’re going to use it,” Selipsky said.

Amazon EC2 Hpc6id Instances: AWS Offers ‘Best Price Performance’
AWS unveiled its new Amazon Elastic Compute Cloud (Amazon EC2) Hpc6id instances for high performance computing (HPC).
“Hpc6id instances are designed to deliver leading price performance for data, memory intensive HPC workloads, higher memory bandwidth, faster local SSD storage and enhanced networking with [AWS] Elastic Fabric Adapter,” said Selipsky. “AWS offers HPC instances with best price performance for each your specific workflow.”
Additionally, Selipsky said the new Hpc6id instances are optimized to efficiently run memory bandwidth-bound, data-intensive HPC workloads such as finite element analysis and seismic reservoir simulations.
“With EC2 Hpc6id instances, you can lower the cost of your HPC workloads while taking advantage of the elasticity and scalability of AWS,” he said.
EC2 Hpc6id instances are powered by 64 cores of 3rd Generation Intel Xeon Scalable processors with an all-core turbo frequency of 3.5 GHz, 1,024 GB of memory, and up to 15.2 TB of local NVMe SSD storage, according to AWS.
EC2 Hpc6id instances, built on the AWS Nitro System, offer 200 Gbps Elastic Fabric Adapter networking for high-throughput inter-node communications that enable customers HPC workloads to run at scale.

AWS SimSpace Weaver: Focus On Building ‘This Expansive World Instead Of Managing Infrastructure
AWS announced AWS SimSpace Weaver, a new fully managed compute service that helps users deploy large-scale spatial simulations in the cloud.
With SimSpace Weaver, you can create seamless virtual worlds with millions of objects that can interact with one another in real time without managing the backend infrastructure, Selipsky said.
“The SimSpace Weaver allows you to stay focused on building more simulation code and creating the content to build this expansive world instead of managing infrastructure,” said Selipsky.
“With SimSpace Weaver, you could run large scale simulations without being constrained by a single piece of hardware or having to manage the underlying memory or networking infrastructure,” he said. “This means that developers can spend more time building and understanding their simulations and less time deploying and scaling.”
SimSpace Weaver manages the complexities of data replication and object transfer across Amazon EC2 instances so that you can spend more time developing simulation code and content. Customers can use their own custom simulation engine or popular third-party tools such as Unity and Unreal Engine 5 with SimSpace Weaver.
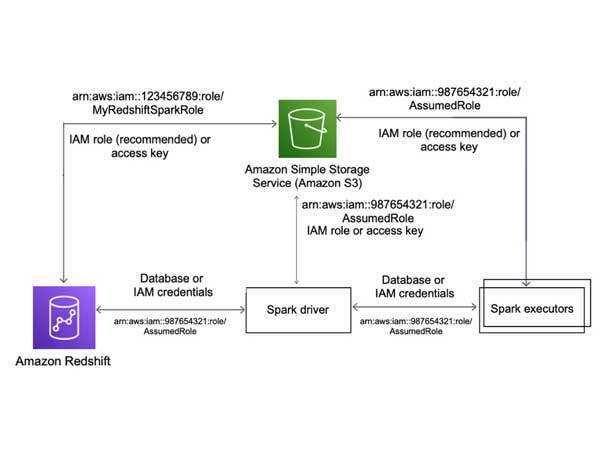
Amazon Redshift Integration For Apache Spark: ‘Fast And Seamless’
Amazon Redshift is now integrated with Apache Spark to help data engineers build and run Spark applications that can consume and write data from an Amazon Redshift cluster.
“Today if you’re working in EMR, you can use Spark to run analytics on data. But if you want to run a Spark query for data located in Redshift, you have to either move the data into S3 or find, download, and configure slow open source container to connector to Redshift. A better way would be to just run a Spark query on the data right in Redshift,” said Selipsky in his keynote. “So we wanted to make fast and seamless and I’m really excited to introduce Amazon Redshift integration for Apache Spark.”
Amazon Redshift integration for Apache Spark can now help developers seamlessly build and run Apache Spark applications on Amazon Redshift data.
If customers are using AWS analytics and machine learning services—such as Amazon EMR, AWS Glue, and Amazon SageMaker—they can now build Apache Spark applications that read from and write to their Amazon Redshift data warehouse without compromising on the performance of applications or transactional consistency of data.
“Now it’s incredibly easy to run Apache Spark applications on rRedshift data from AWS analytic services,” said the AWS CEO. “There’s now no more need to move any data, no need to build or manage any connectors.”
Selipsky said Amazon Redshift integration for Apache Spark minimizes the cumbersome and often manual process of setting up a Spark-Redshift open-source connector and reduces the time needed to prepare for analytics and ML tasks.