The 21 Hottest Products At Nvidia GTC 2024
Nvidia over the years has built a huge ecosystem of the IT industry’s top hardware and software manufacturers who build cutting-edge products based on its GPU and other technologies. This week, the Nvidia GTC event provided a forum for showcasing some of those new hardware and software products.

Nvidia’s Huge Partner Ecosystem Shines At GTC
Nvidia’s annual Global Technology Conference, a.k.a. GTC, is being held this week live for the first time in nearly five years, and is showcasing not only the latest in Nvidia’s GPU and other technologies, but also what a large ecosystem of technology partners are doing around that company’s latest offerings.
Nvidia this week is using GTC to release multiple new technologies. These include its next-generation Blackwell GPU architecture, the much-hyped successor to Nvidia’s Hopper platform, claiming it will enable up to 30 times greater inference performance and consume 25 times less energy for massive AI models.
Nvidia also used the conference to launch its Blackwell-powered DGX SuperPOD aimed at generative AI supercomputing at the trillion-parameter scale, new switches optimized for trillion-parameter GPU computing and AI, GenAI microservices for developers, and more.
[Related: Nvidia’s 10 New Cloud AI Products For AWS, Microsoft And Google]
Nvidia, however, was not the only company pushing GPU-powered AI and other workloads. GTC also lets a wide range of technology partners showcase their own offerings either based on or integrated with one of several new Nvidia technologies.
Those partners showed new servers, semiconductors, software, middleware, and other products taking advantage of the Nvidia ecosystem. Most, if not nearly all, of those new products were aimed at helping businesses take advantage of the AI capabilities of the Nvidia technologies, and the new generative AI possibilities, particularly around its latest GPUs.
These included new offerings aimed at improving the cyber resiliency around AI, improvements around GPU utilization, increasing the analytics around AI, improved AI inferencing capabilities, better conversational capabilities, and improved AI training.
There is a lot happening in the Nvidia GPU and AI ecosystem. Click through the slideshow to see how 21 of Nvidia’s technology partners are building on what the company has to offer.
Balbix BX4 AI Engine
Balbix, a San Jose, Calif.-based developer of AI-powered cyber risk management technology, used GTC 2024 to introduce the general availability of its new Balbix BX4 engine. The Balbix BX4 engine powers Balbix AI and works with NVIDIA-powered GenAI, deep learning, and other specialized machine learning techniques to analyze millions of assets and vulnerability instances as a way to enhance cyber risk management when identifying critical vulnerabilities and evaluating security efficacy, the company said.
Balbix BX4 leverages the full-stack Nvidia AI platform and Nvidia GPUs, and integrates Nvidia Triton Inference Server, Nvidia TensorRT-LLM, and other technologies to train large language models (LLMs). These LLMs power asset analysis, vulnerability, and risk models to give cybersecurity professionals real-time, actionable insights into risk reduction.
ClearML Beefs Up GPU Management
ClearML, a Tel Aviv, Israel-based developer of enterprise AI technology, introduced a free open source tool to help businesses optimize their GPU utilization. The tool lets DevOps and AI infrastructure people take advantage of Nvidia’s time-slicing technology to partition their Nvidia GTX, RTX and MIG-enabled GPUs into smaller fractional GPUs to support multiple AI and HPC workloads without the risk of failure and optimize their infrastructure for GenAI workloads.
ClearML also introduced new ways to better control AI infrastructure management and compute costs. The company’s new Resource Allocation & Policy Management Center provides advanced user management to improve quota management, priority, and granular control of compute resources. And its new Model Monitoring Dashboard allows the viewing of all live model endpoints and monitoring of their data outflows and compute usage.

Dell Expands AI Infrastructure Capabilities
Dell Technologies went big at GTC with the introduction of a number of technologies aimed at strengthening customers’ infrastructure for AI.
New is the Dell AI Factory with Nvidia, which integrates Dell’s compute, storage, client device, and software capabilities with Nvidia’s AI infrastructure and software suite along with a high-speed networking fabric. Dell AI Factory is delivered jointly with Nvidia and Dell Services as a fully integrated, rack-level offering designed for enterprise data security and governance standards.
Also new at GTC were Dell PowerEdge XE9680 servers that support the latest Nvidia GPU models, including the Nvidia HGX B100, B200, and H200 Tensor Core GPUs; a Dell-Nvidia full-stack technology for RAG (retrieval-augmented generation); AI model training with Dell Generative AI Solutions with Nvidia; and Dell Data Lakehouse to help businesses discover, process, and analyze data in one place across hybrid and multicloud environments.
Kinetica Real-time Inferencing
Kinetica, an Arlington, Va.-based developer of real-time GPU-accelerated analytics, used GTC 2024 to introduce an enterprise GenAI technology solution for enterprise customers powered by Nvidia NeMo and Nvidia accelerated computing infrastructure to instantly enrich GenAI applications with domain-specific analytical insights derived directly from the latest operational data.
Kinetica has also built native database objects that let users define the semantic context for enterprise data so that an LLM can use such objects to grasp the referential context it needs to interact with a database in a context-aware manner.
For developers, Kinetica provides relational SQL APIs and LangChain plugins to help them harness all the enterprise-grade features that come with a relational database, including control over who can access the data via role-based access control, reduce data movement from existing data lakes and warehouses, and preserve existing relational schemas
Kinetica said its real-time GenAI technology solution removes the need for reindexing vectors before they are available for query, and lets it ingest vector embeddings 5X faster than the previous market leader, based on the VectorDBBench benchmark.

Pure Storage Validated Reference Architecture For AI
Pure Storage, the Santa Clara, Calif.-based all-flash storage pioneer, introduced new validated reference architectures designed jointly with Nvidia for GenAI cases. They include:
- Retrieval-augmented generation (RAG) pipeline for AI inference – This is a RAG pipeline built with Nvidia NeMo Retriever microservices, Nvidia GPUs, and Pure Storage all-flash storage. It is aimed at increasing the performance of internal data for AI training to reduce the need for constant LLM retraining.
- Certified Nvidia OVX server storage reference architecture – Based on Pure Storage’s 2023 certification for Nvidia DGX BasePOD, this architecture provides flexible storage as an infrastructure foundation for cost-optimized and performance-optimized AI hardware and software.
- Vertical RAG deployment – This RAG technology is targeted at summarizing and querying massive data sets with better accuracy than off-the-shelf LMMs for financial institutions.
- Expanded relationships with third-party software developers including Run.AI and Weights & Biases.
Edge Impulse: Running Nvidia TAO On The Edge
San Jose, Calif.-based Edge Impulse, which develops a platform for building and deploying machine learning models and algorithms to edge devices, used GTC to unveil new tools developed using Nvidia’s Omniverse and AI platforms to transfer the power of Nvidia TAO models from GPUs to any edge device. Nvidia TAO lets users choose one of over 100 pre-trained AI models from the Nvidia NGC curated set of GPU-optimized software to move from GPUs to run on previously inaccessible class of devices on the edge, including MCUs and MPUs.
The Edge Impulse and NVIDIA TAO Toolkit lets engineers create accurate, custom, production-ready computer vision models that can be deployed to edge-optimized hardware, including the Arm Cortex-M based NXP I.MXRT1170, Alif E3, STMicroelectronics STM32H747AI, and Renesas CK-RA8D1. It lets users provide their own custom data.
Heavy.AI HeavyIQ
San Francisco-based Heavy.AI used GTC to unveil HeavyIQ which brings LLM capabilities to the GPU-accelerated Heavy.AI analytics platform to help organizations interact with their data through conversational analytics. Heavy.AI claims it allows users to more easily explore their data with natural language questions and to generate advanced visualizations of that data in a streamlined process that can reduce the friction of traditional business analytics.
HeavyIQ has trained an open-source LLM foundation model to excel at core analytics tasks, including analyzing massive geospatial and temporal data sets, Heavy.AI said. It provides the power of an LLM in conjunction with retrieval augmented generation (RAG) capabilities to automatically convert a user’s text input into an SQL query, and can both visualize and return natural language summaries of results.
Future HeavyIQ releases are slated to take advantage of the Nvidia NeMo inference framework to increase performance and scalability.

Phison LLM Training, SSDs
Hsinchu, Taiwan-based Phison demonstrated its new aiDAPTIV+ hybrid hardware and software technology for fine-tuning foundational training of LLMs to help deliver precise results for business needs, along with partnerships with hardware companies including Asus, Gigabyte, Maingear, and MediaTek. Phison also unveiled new X200 SSDs supporting 14GB/sec. and up to 32-TB density in U.2/U.3 and E3.S form factors.

Maingear PRO AI Workstations With aiDAPTIV+
Maingear, a Warren, N.J.-based developer of workstations, used GTC 2024 to introduce its new Maingear PRO AI workstations featuring intelligent SSD caching to handle large-scale AI models. The new workstations also feature Phison’s aiDAPTIV+ technology which was designed to make LLM development and training useful for SMBs at a lower cost than traditional AI training servers.
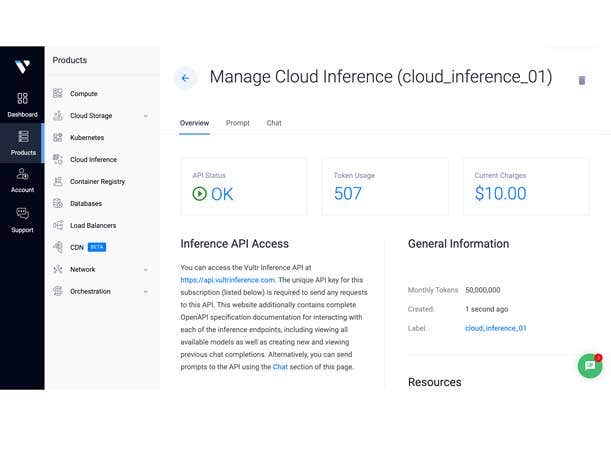
Vultr Cloud Inference
West Palm Beach, Fla.-based Vultr, a developer of a privately held cloud computing platform, used GTC to introduce its new Vultr Cloud Inference, a new serverless platform for scaling AI and providing global AI model deployment and AI inference capabilities. Vultr Cloud Inference leverages Vultr’s global infrastructure, which spans 32 locations over six continents, to give customers’ AI deployments seamless scalability, reduced latency, and enhanced cost efficiency, the company said.
Vultr Cloud Inference can accelerate the time-to-market of AI-driven features, such as predictive and real-time decision-making. Users seamlessly integrate and deploy their own model, trained on any platform, cloud, or on-premises, on Vultr’s global Nvidia GPU-powered infrastructure. With dedicated compute clusters available on six continents, Vultr Cloud Inference helps businesses deploy AI applications in any region to comply with local data sovereignty, data residency, and privacy regulations.

Lenovo Hybrid AI Systems
Lenovo unveiled a series of AI servers and AI workstations aimed at using Nvidia technology to bring GenAI capabilities to enterprises of any size and provide developers access to the just-announced Nvidia microservices, including Nvidia NIM and NeMo Retriever.
New from Lenovo are two Lenovo ThinkSystem AI 8-way Nvidia GPU-based servers engineered for GenAI, natural language processing (NLP), and LLM development. They include time-to-market support for the Nvidia HGX AI supercomputing platform, including Nvidia H100 and H200 Tensor Core GPUs and the new Nvidia Grace Blackwell GB200 Superchip, as well as the next-generation Nvidia Quantum-X800 InfiniBand and Spectrum-X800 Ethernet networking platforms.
Lenovo also introduced other AI servers featuring Intel or ARM processors with Nvidia GPUs, and showed new MGX modular servers co-designed with Nvidia, including air-cooled and liquid-cooled models.
On the workstation side, the company introduced new Lenovo ThinkStation Workstations with up to four Nvidia RTX 6000 Ada Generation GPUs for large AI training, fine-tuning, inferencing, and accelerated graphics-intensive workloads. The company also introduced new AI PCs and mobile PCs.

DDN AI400X2 Turbo
DDN, a developer of some of the world’s highest-performance storage systems, introduced its new DDN AI400X2 Turbo, describing it as a power-efficient storage system aimed at both AI and high-performance software stacks and AI libraries.
DDN said its 2U-format AI400X2 Turbo storage appliance delivers improved ROI for multi-node GPU clusters as well as GenAI, Inference, AI frameworks, and software libraries, with its 75-GB/sec. write speeds and 120-GB/sec. read speeds.

UneeQ Synamin and Nvidia
UneeQ, an Austin, Texas-based developer of technology that uses GenAI to build digital representatives of human to interact with customers, used GTC to show its proprietary synthetic animation, or Synamin, AI animation system is leveraging the Nvidia Avatar Cloud Engine (ACE) for digital human interaction.
UneeQ is deploying Nvidia Audio2Face, part of Nvidia ACE, a suite of technologies that enables real-time digital humans to be even more lifelike aimed at garnering positive customer interactions. The use of Audio2Face speeds up response time to deliver higher conversions, improved customer service and customer journeys, better staff training, and enhanced web and immersive experiences, the company said.

Supermicro Nvidia-based GenAI SuperClusters
San Jose, Calif.-based server, storage, and AI systems manufacturer Supermicro introduced a new portfolio of three Supermicro SuperCluster systems featuring Nvidia GPUs and aimed at GenAI workloads.
They include a 4U liquid-cooled system with up to 512 GPUs in 64 nodes across five racks and an 8U air-cooled system with 512 GPUs in 32 nodes across nine racks. Both include Tensor Core GPUs, 400 Gigabit-per-second storage connectivity to each GPU, as well as 400-Gbit InfiniBand or 400-GbitEthernet switch fabrics. The third system is a 1U air-cooled system with up to 256 Grace Hopper Superchips across 9 racks.

ASRock Rack Servers Supporting Nvidia Blackwell
Taipei, Taiwan-based server manufacturer ASRock Rack used GTC to introduce several new servers, including the 6U8X-EGS2 AI training systems. The 6U8X-EGS2 features up to eight Nvidia H100 or Nvidia H200 GPUs in a 6U rackmount form factor, as well as 12 PCIe Gen5 NVMe drive bays and multiple PCIe 5.0 x16 slots, as well as a 4+4 PSU (power supply units) for full redundancy.
ASRock Rack is also developing servers to support the new NVIDIA HGX B200 8-GPU aimed at GenAI applications, LLM acceleration, and data analytics and high-performance computing workloads.

Check Point AI Cloud Protect
Check Point Software, a Redwood City, Calif.-based developer of cloud-delivered cyber security, unveiled a strategic partnership with Nvidia at GTC aimed at enhancing the security of AI cloud infrastructure. Under the partnership, Check Point’s new AI Cloud Protect technology is integrated with Nvidia’s DPUs (digital processing units) to help stop security threats at both the network and host levels.
The partnership between Check Point and Nvidia’s BlueField 3 DPU and DOCA framework integrates network and host-level security insights as part of a comprehensive offering aimed at protecting AI infrastructures from both conventional and novel cyber threats while remaining cognizant of network activities and host-level processes that are crucial for safeguarding AI's future. It offers out-of-the-box security to protect against sophisticated cyber threats with fast deployment without impacting AI performance, Check Point said.

Cognizant And Nvidia BioNeMo
Global solution provider Cognizant and Nvidia at GTC unveiled a global strategic partnership to apply GenAI to enhance the drug discovery process for pharmaceutical clients. The partnership combines Nvidia’s BioNeMo platform and Cognizant’s deep life sciences and AI domain expertise to provide pharmaceutical businesses access to a suite of model-making services to help accelerate how they can harness proprietary data to develop and market new treatments.
The goal of the partnership is to quickly process drug discovery methodologies and analyze vast repositories of scientific literature and clinical data to reveal relevant insights, all while reducing the costs and long development lifecycles of such research utilizing GenAI technologies.
Cognizant said it is also pursuing additional applications by collaborating with Nvidia in areas such as manufacturing and automotive engineering where GenAI has the potential to enhance productivity, reduce costs, and speed up innovation.
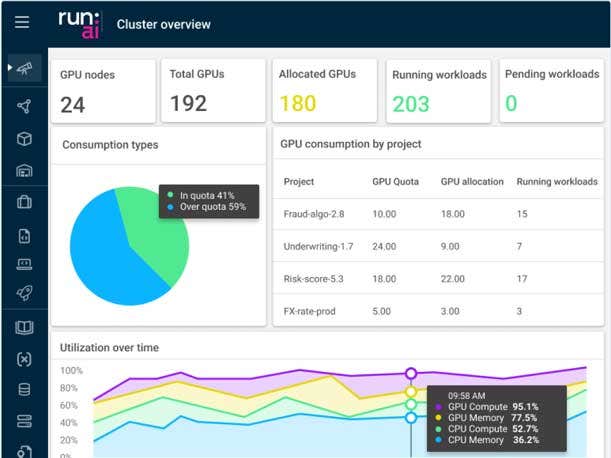
Run:ai Gets Nvidia DGX SuperPOD Certification
Tel Aviv, Israel-based Run:ai, which develops AI optimization and orchestration technology, said at Nvidia GTC that it has received Nvidia DGX SuperPOD certification. The collaboration between the two companies brings Run:ai’s advanced workload management capabilities to the Nvidia DGX SuperPOD, letting businesses easily run their AI and machine learning projects while accommodating the growing requirements of GenAI and LLMs and making AI technologies more accessible to a broader audience.
Run:ai’s orchestration platform allows for the dynamic allocation and efficient utilization of GPU resources, while its Run:ai Dev provides comprehensive support across the AI development lifecycle. The Run:ai Control Plane integrates business rules and governance, while Logical AI Clusters enable the seamless scaling of AI operations, the company said.

ZutaCore HyperCool Liquid Cooling Technology
ZutaCore’s HyperCool Liquid Cooling Technology supports Nvidia’s H100 and H200 GPUs for sustainable AI, the San Jose, Calif.-based company said at GTC. ZutaCore introduced its first waterless dielectric cold plates for the H100 and H200 GPUs as a way to keep those chips cool to help maximize AI performance.
ZutaCore said that the H100 and H200 GPUs can consume 700 Watts of power which can challenge data center heat, energy consumption, and footprint. ZutaCore’s direct-to-chip waterless two-phase liquid cooling technology, which it calls HyperCool, was designed to cool powerful processors of 1,500 watts or more.
Among ZutaCore’s partners are data center company Mitsubishi Heavy Industries, system integrator Hyve Solutions, and server vendors including Dell Technologies, ASUS, Pegatron, and Supermicro.

Pliops XDP-AccelKV
Pliops, a Santa Clara, Calif.-based developer of processors for cloud and enterprise data centers, introduced the Pliops XDP-AccelKV universal data acceleration engine at GTC, saying the engine significantly minimizes the scalability challenges of AI/Gen AI applications. It addresses GPU performance and scale by both breaking the GPU memory wall and eliminating the CPU as a coordination bottleneck for storage IO to extend HBM memory with fast storage to enable terabytes-scale AI applications to run on a single GPU.
XDP-AccelKV is part of Pliops’ XDP Data Services platform, which runs on the Pliops Extreme Data Processor (XDP). That platform helps maximize data center infrastructure investments by increasing application performance, storage reliability and capacity, as well as overall stack efficiency.
Pliops has also collaborated with Westminster, Colo.-based Liqid to create an accelerated vector database solution that combines Dell servers, Liqid’s LQD450032TB PCIe 4.0 NVMe SSDs, and managed by Pliops XDP.
NetApp Collaborates With Nvidia On RAG
Storage and cloud powerhouse NetApp is working with the new Nvidia NeMo Retriever microservices to let every NetApp Ontap customer seamlessly “talk to their data” to access proprietary business insights without compromising the security or privacy of their data.
NetApp and Nvidia together are using Nvidia NeMo Retriever microservices technology for retrieval-augmented generation (RAG) that can leverage any data stored on NetApp Ontap, whether it is on-premises or in a public cloud. This lets NetApp customers query their data, whether spreadsheets, documents, presentations, technical drawings, images, meeting recordings, or even data from ERP or CRM systems, via simple prompts, all while maintaining the access control they’ve already established when storing the data.