AWS Summit: 5 New Aurora, IoT TwinMaker And Glue Offerings
CRN breaks down five new AWS offerings unveiled today at AWS Summit during Swami Sivasubramanian’s keynote speech.
AWS Summit Keynote: Sivasubramanian Unveils New Offers
Amazon Web Services launched a slew of offerings at its AWS Summit event today in San Francisco around its Aurora Serverless, IoT TwinMaker, Amplify Studio and AWS Glue cloud solutions.
Swami Sivasubramanian, vice president of data, analytics, and machine learning services at AWS, unveiled the new innovations during his keynote address—touting AWS’ strategy of hiring builders and inventors.
“We hire builders who are always thinking about inventing on behalf of customers, looking for ways to simplify, and they do not accept the premise that we have to build things a certain way because this is how things are always done,” said Sivasubramanian on stage during his AWS Summit keynote speech.
New product launches on Thursday revolved around AWS’ cloud relational database solution Aurora; AWS IoT TwinMaker, which creates digital twins of real-world systems along with management capabilities; Amplify Studio for building and shipping web and mobile applications at speed; and AWS Glue for serverless data integration.
In his keynote, Sivasubramanian touted how the benefits of AWS services are convincing businesses of all shapes and sizes to migrate to the cloud.
“The benefits of the cloud are so strong that virtually every workload and application is either running in the cloud today, or it’s moving to the cloud as quickly as possible. And analytics and big data workloads are no exception,” said Sivasubramanian. “The opportunity to analyze data at very large scale, at speed and low cost, are second to none on AWS.”
Sivasubramanian first joined Amazon in 2006, rising from the rank of principal engineer to general manager of AWS’ NoSQL and analytics business within a few years. He became one of AWS’ top executives for machine learning in 2017, before taking on his current role of managing AWS’ database, analytics and machine learning services.
Here is what Sivasubramanian said on stage during his keynote at AWS Summit regarding the launch of five new offerings.

Aurora Serverless v2: On-Demand Autoscaling Configuration For Aurora PostgreSQL And MySQL
Given how popular relational databases are, it should be no surprise that customers use a lot of Amazon Aurora. Since actually launching in 2014, Aurora has grown at a staggering pace, with a 10X increase in the last four years alone. It continues to be the fastest growing AWS service.
Now, as customers are growing their usage of Aurora and building more and more complex apps, their applications are also growing in complexity and size. As they experience this growth, they have been asking us for ways to make it simpler and easier to scale.
That’s why today we are really excited to announce the general availability of our Amazon Aurora Serverless v2.
Aurora Serverless v2 is the result of extensive conversations with customers specifically around the scaling behavior. ‘How could we deliver a better relational database with a serverless operating model?’
Some of these improvements are around how do we scale in smaller increments such as: We want to be able to scale to hundreds-of-thousands of transactions per second, not in double-digit seconds, but in just a single second. And having fine-grained scaling instruments to provide just the right amount of database resources as needed.
Aurora Serverless v2 also includes features users love, such as global database read replicas and multiple AZ [Availability Zones] support. We wanted customers of all sizes to experience the benefits of serverless and with Aurora Serverless v2, we can now support enterprises with hundreds to thousands of applications and associated databases.

AWS IoT TwinMaker: Create Digital Twins Of Real-World Systems
We are really pleased to announce the general availability of AWS IoT TwinMaker, our service that makes it easier for developers to create digital twins of real-world systems like buildings, factories, industrial equipment and production lines.
TwinMaker allows you to use your existing IoT, video, and enterprise application data where it already lives without needing to ingest or move the data to another location.
[For example] by importing your 3D models directly into the service, you can then create immersive 3D visualizations of your real-world environment—showing real time data, video and insights. This TwinMaker automatically builds out a knowledge graph that helps catalog the entities and relationships in our environment.
TwinMaker also provides a plugin for Grafana so you can also create a unified view of all the relevant data to help you monitor things more effectively. This unified view empowers your operators to move quickly and detect and diagnose problems when they occur—reducing the total cost of equipment outages. We are really looking forward to seeing how TwinMaker helps continue to improve field operations for many of our industrial customers.
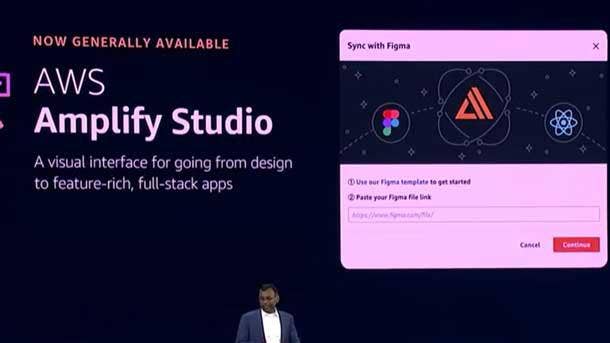
AWS Amplify Studio: Simplifies Front- and Back-End Development For Web And Mobile Apps
When I talk to front-end web developers and ask them some challenges they are facing, these are some of the common ones that pop up. First, they’re always looking for ways to add common back-end functionality to their application, but they lacked the subject matter expertise to do so from scratch. Second, they are trying to accelerate their work with UX designers. They want to be able to move more quickly and go from designs to working functionalities even faster. They need tools that leverage their skillsets to accomplish their tasks, implement front end UI designs, and build extensive full-stack applications much faster.
To help developers with this, I’m really excited to announce the general availability of AWS Amplify Studio.
Developers can now use AWS Amplify Studio to quickly set up an extensible backend, in hours, instead of what used to be weeks. Also [they can] visually create feature rich UIs and connect together all within the studio—no cloud or AWS expertise is required.
Amplify Studio helps bridge application design, development, and product with the same tools customers love. All UI components are fully customizable with popular design and prototyping to [collaboration interface design tool] Figma—giving designers complete control over the visual styling of components. And developers can do all of this at no cost on AWS.

AWS Glue Autoscaling: Scale Workers Based On Workload
Unifying data is not just about storing this data, but it’s also about unifying access. For this, we have AWS Glue, our fully serverless data integration service that lets you discover, prepare, and integrate all of your data. When we launched AWS Glue in 2017, we had the vision to make it faster, easier and more cost effective for companies to scale and modernize ETL [extract, transform and load] pipelines and do it all in one place. But when it comes to ETL and data integration, it can be hard to predict how this data integration work will happen at times.
There are constant fluctuations in data volume and demand over time. Data engineers must constantly monitor and experiment to right-size for the performance they need and for the cost they can actually bear. This is hard and tedious engineering work. There are tradeoffs: You are either under provisioning your infrastructure, thereby taking a hit on performance, or over provisioning, thereby taking a hit on costs.
We saw this as an undifferentiated heavy lifting and wanted to relieve customers of this burden. That’s why we automated this process.
We are excited to announce the general availability of AWS Glue Autoscaling.
While Glue is already serverless, the challenge of automizing the number of workers that you need to process in your ETL pipeline made it really challenging for data engineers. Now with Autoscaling in AWS Glue, it dynamically scales the workers count, up and down, based on your data pipeline needs. This makes it even easier to right size the infrastructure for your ETL job, so that you are paying exactly for the resources you need, and nothing more.
Glue adds and removes resources depending on how much it can split up the workload. You no longer need to worry about over provisioning resources or under provisioning them. Thereby freeing up valuable time of data engineers and reducing compute costs.

AWS Glue Sensitive Data Detection
A common conversation I have with customers is around how they can become more effective at handling sensitive data. When I talk about sensitive data, that means things like tax ID numbers, names and medical information. However, finding sensitive data in data lakes is like finding a needle in an ever-growing haystack.
Data volume is always growing. Sensitive data can be found anywhere. Finally, the problem of finding that sensitive information is really hard. You have to build techniques to detect all types of sensitive data in the pipelines and in your data lake.
To address this challenge, I’m really excited to announce the general availability of Sensitive Data Detection in AWS Glue.
This feature can help identify sensitive data while it’s still in your data pipeline so that you can even prevent that data from landing in your data lake.
It can also pinpoint the locations of sensitive data already in your database so you can detect, redact, replace, or report on that data. The best part is it works at scale and it is completely serverless. So now sensitive data detection has never been easier and more cost effective.